

前言
现代电脑都支持多线程,目前个人电脑基本都是16线程起步,一个优秀的软件应该有调用多线程加快运行速度的能力,那Vivado满足这个优秀的条件吗?
本文将测试Vivado的多线程编译能力,先说结论:
-
设置Vivado最大线程为32,有助于提升编译速度;
-
Vivado最多能利用的线程数应该是16。
好吧,从结论看Vivado勉强可以称为优秀吧,毕竟是最好用的FPGA开发工具,且是断层领先的那种。
具体测试详见正文。
一、什么是最大线程和使用线程
Vivado有最大线程限制,默认为2。可在Tcl Console窗口输入以下命令查看最大线程。
get_param general.maxThreads
可用以下命令设置最大线程。
set_param general.maxThreads 32
使用方法如下图所示。
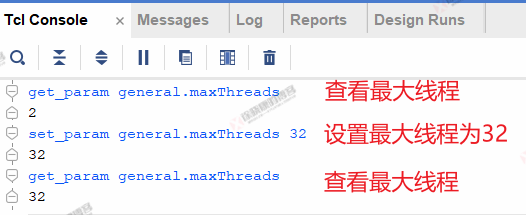
上述命令仅在当前打开的Vivado中生效,关闭Vivado再打开后需要重新设置。
一种永久设置最大线程的办法是在Vivado安装路径的scripts文件夹中新建Vivado_init.tcl,将set_param general.maxThreads 32命令添加到此tcl文件中,如下图所示,Vivado启动会自动加载此文件。
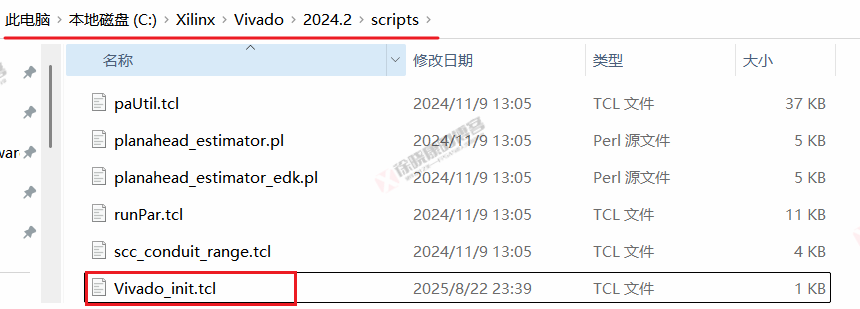
详细教程请参考:https://blog.csdn.net/weixin_42837669/article/details/115269531?spm=1011.2415.3001.5331
无论最大线程怎么设置,在编译时,都会弹出一个对话框,让我们选择用本机的多少jobs来进行编译,如下图所示。
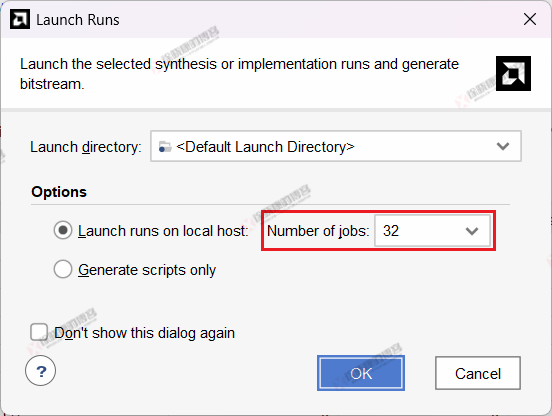
这里的job就是线程的意思,因为你会发现,jobs的最大值总是和你电脑CPU的最大线程数一致。我们把这一步设置的线程称为使用线程。
且无论最大线程怎么设置,使用线程总是可以设置成1~电脑最大线程。那我们就有疑问了,
-
最大线程的设置究竟起作用了吗?还是说以使用线程的设置为准? -
Vivado能利用满所有的32线程吗?还是说超过8/16线程就没什么意义了,Vivado软件就无法利用更多线程?
为此,我们进行实验,基本条件如下:
-
测试工程使用前文介绍的三个示例工程; -
Vivado版本固定为Vivado 2024.2。
保持电脑状态不变,通过修改最大线程和使用线程进行多次测试。
二、测试截图
本章展示所有测试工程编译时间统计截图,以Vivado的Design Runs界面展示的Elapsed列时间为准,精确到秒。
2.1 最大线程2,使用线程32
CPU
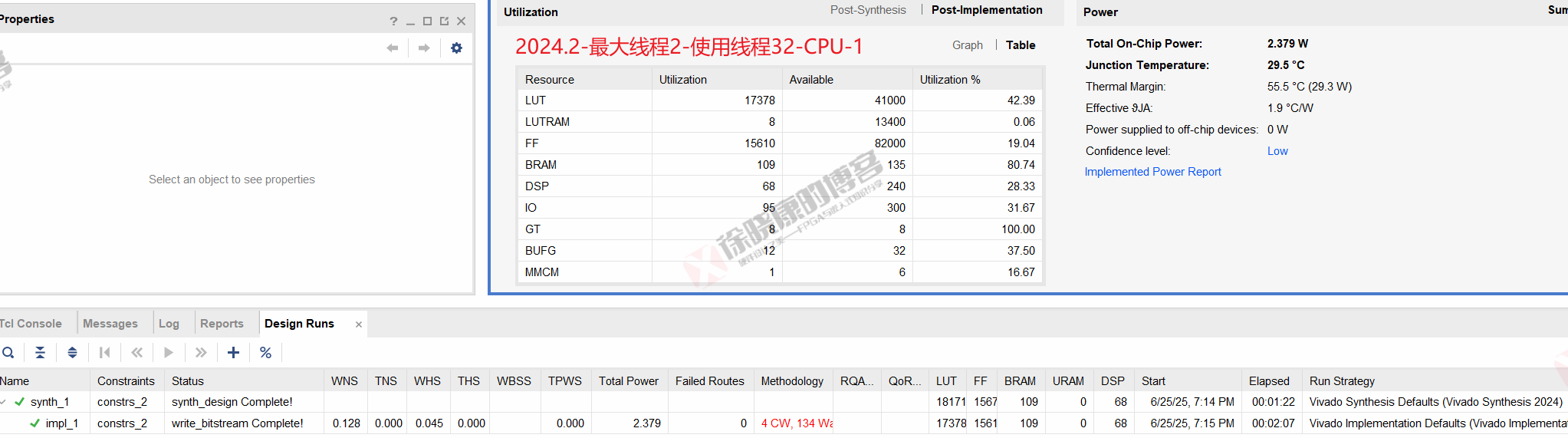
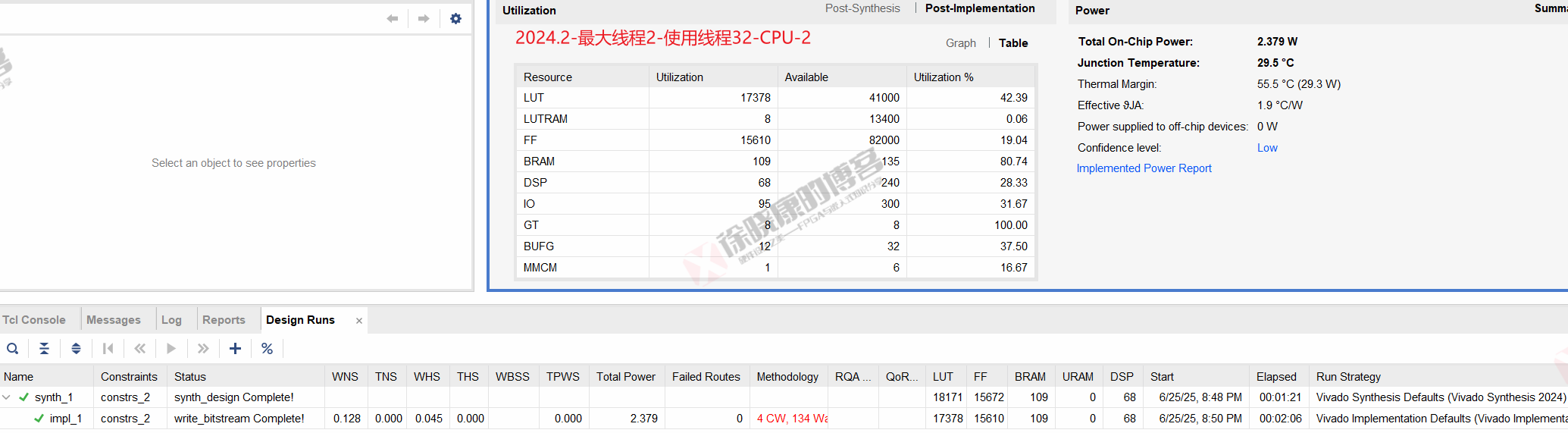
| 实验编号 | OOC | 综合 | 实现 | 合计 |
|---|---|---|---|---|
| 最大线程2,使用线程32-CPU-1 | 0 | 1m22s | 2m07s | 3m29s |
| 最大线程2,使用线程32-CPU-2 | 0 | 1m21s | 2m06s | 3m27s |
| 最大线程2,使用线程32-CPU-平均 | 0 | 1m21.5s | 2m06.5s | 3m28s |
MB
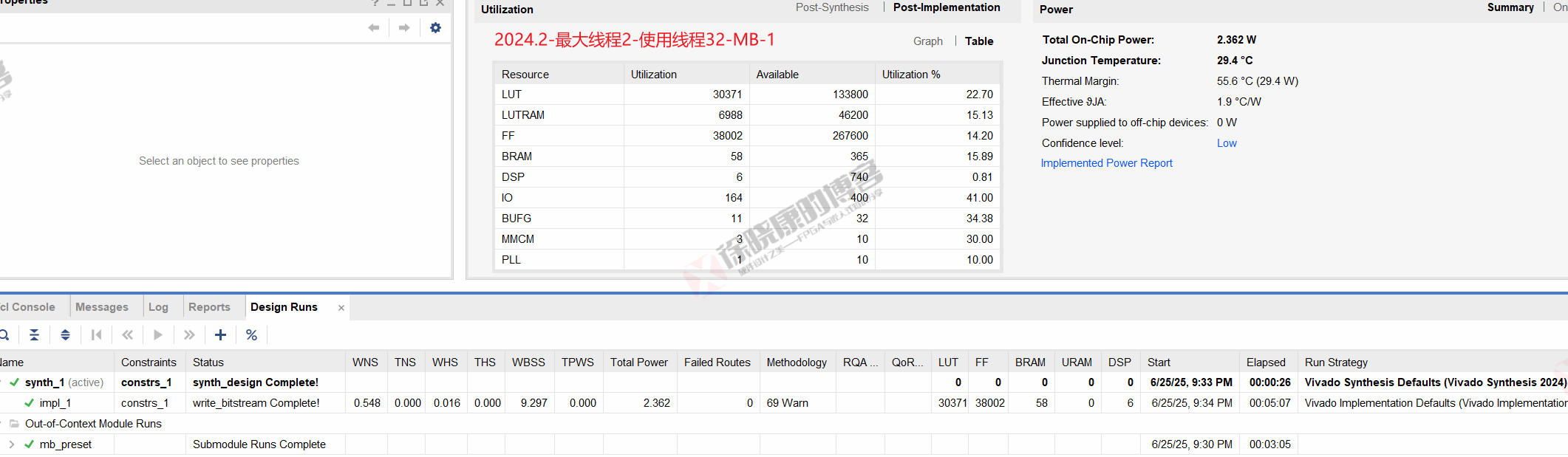
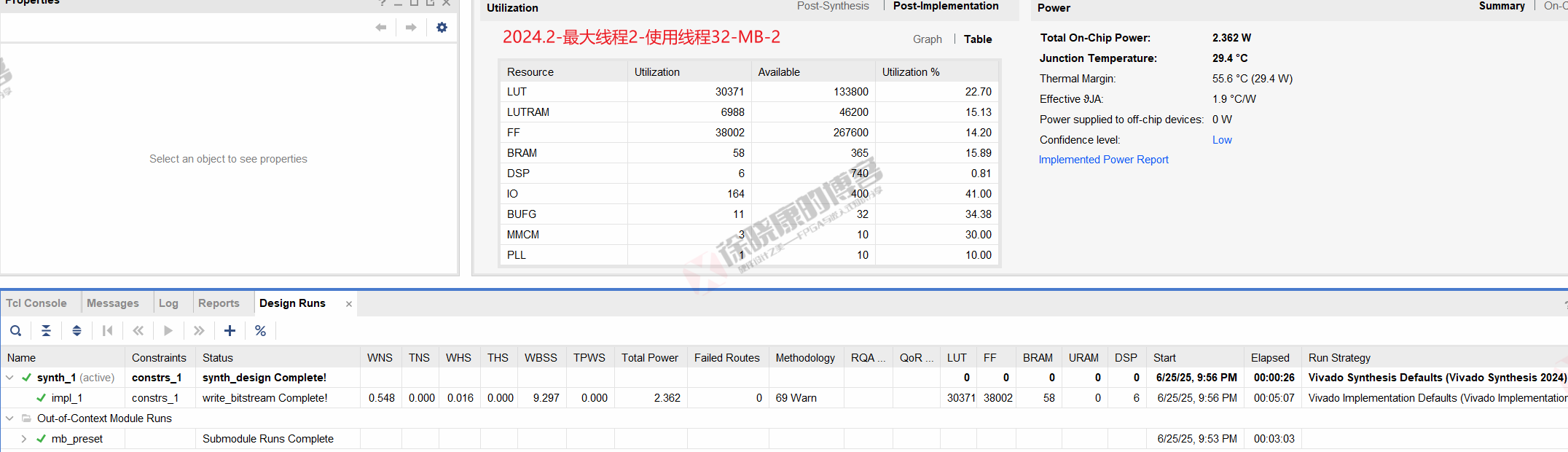
| 实验编号 | OOC | 综合 | 实现 | 合计 |
|---|---|---|---|---|
| 最大线程2,使用线程32-MB-1 | 3m05s | 26s | 5m07s | 8m38s |
| 最大线程2,使用线程32-MB-2 | 3m03s | 26s | 5m07s | 8m36s |
| 最大线程2,使用线程32-MB-平均 | 3m04s | 26s | 5m07s | 8m37s |
ZYNQU
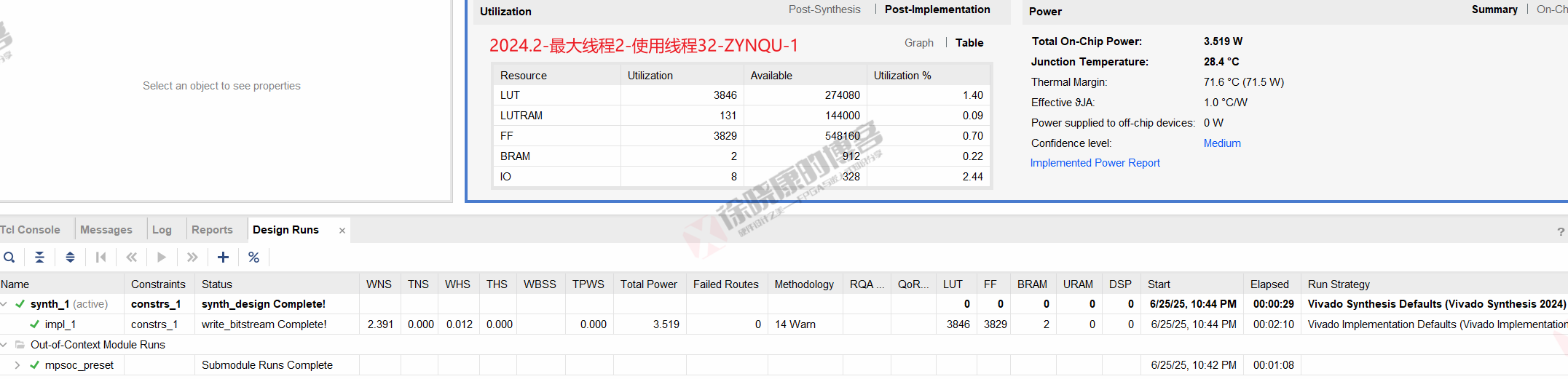
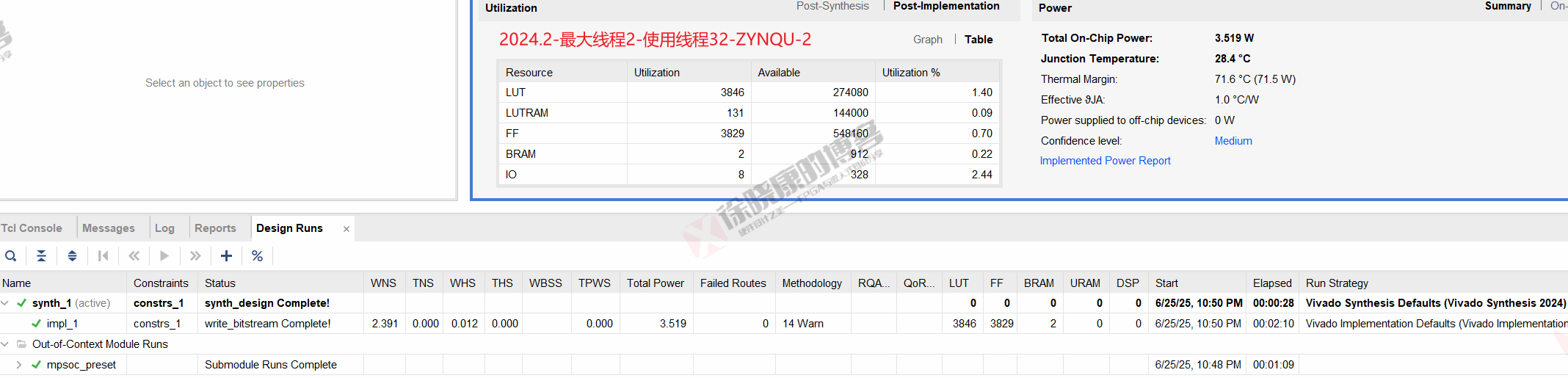
| 实验编号 | OOC | 综合 | 实现 | 合计 |
|---|---|---|---|---|
| 最大线程2,使用线程32-ZYNQU-1 | 1m08s | 29s | 2m10s | 3m47s |
| 最大线程2,使用线程32-ZYNQU-2 | 1m09s | 28s | 2m10s | 3m47s |
| 最大线程2,使用线程32-ZYNQU-平均 | 1m08.5s | 28.5s | 2m10s | 3m47s |
2.2 最大线程32,使用线程32
CPU
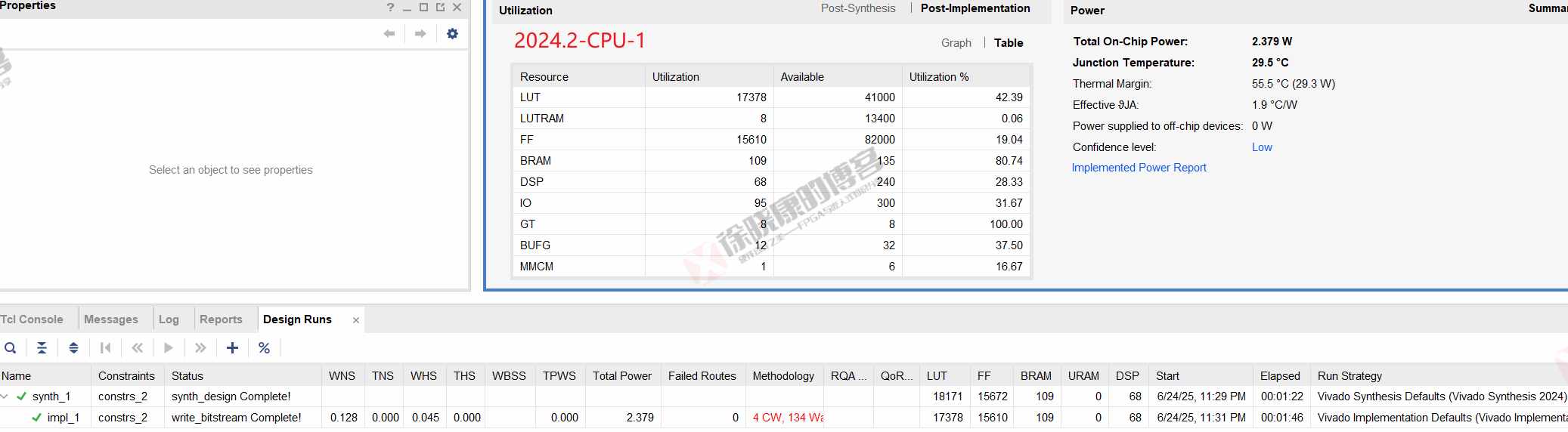
| 实验编号 | OOC | 综合 | 实现 | 合计 |
|---|---|---|---|---|
| 最大线程32,使用线程32-CPU-1 | 0 | 1m22s | 1m46s | 3m08s |
| 最大线程32,使用线程32-CPU-2 | 0 | 1m22s | 1m48s | 3m10s |
| 最大线程32,使用线程32-CPU-平均 | 0 | 1m22s | 1m47s | 3m09s |
MB
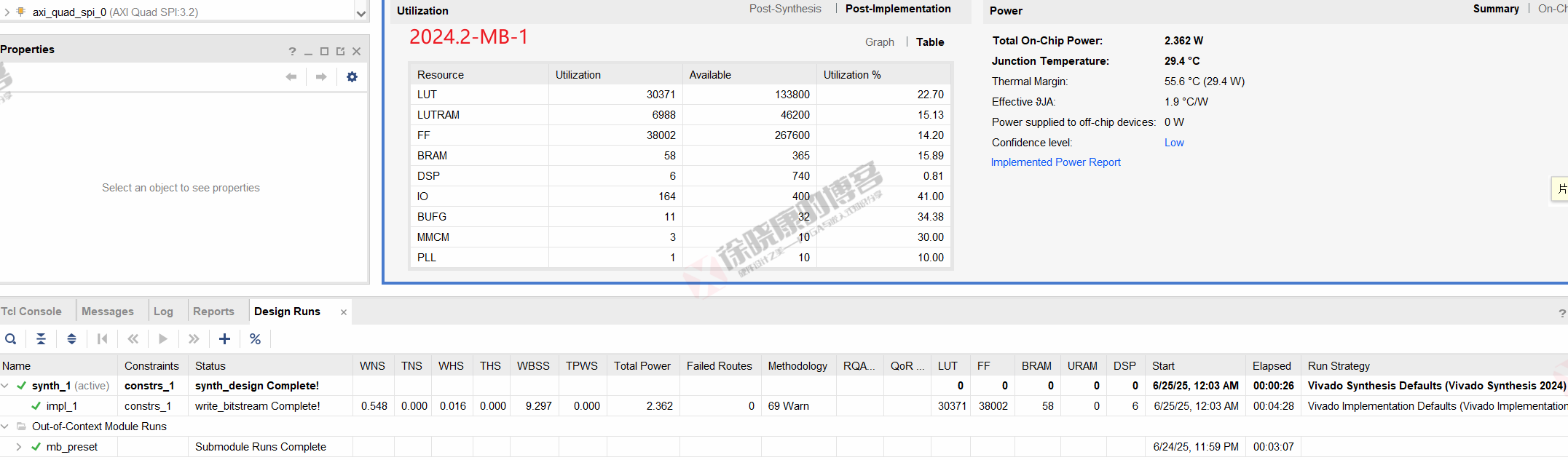
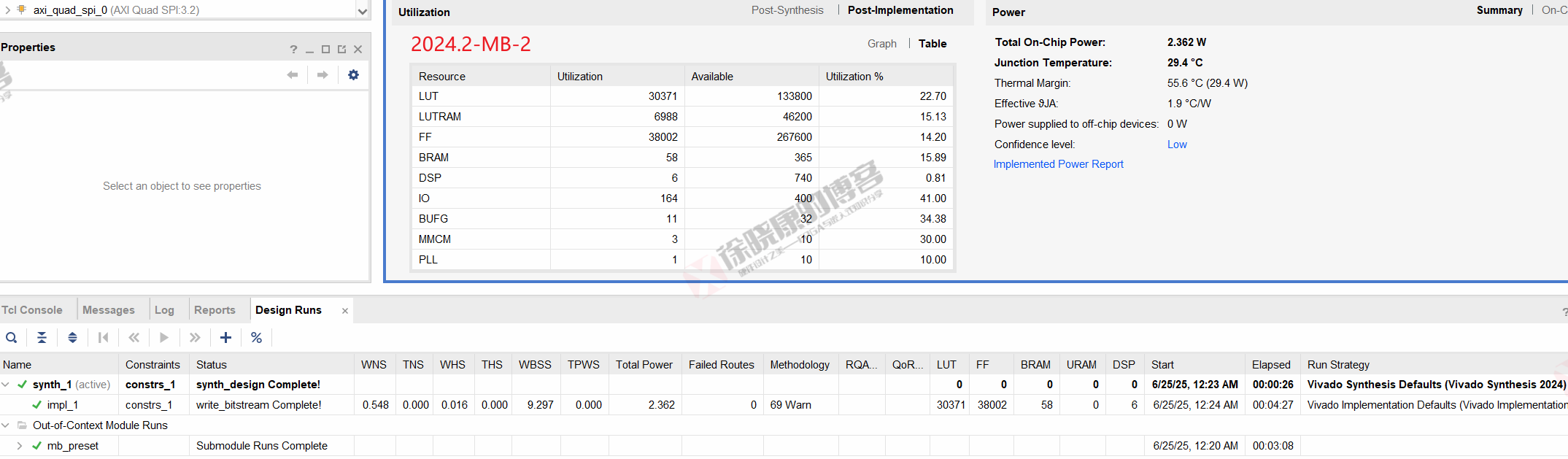
| 实验编号 | OOC | 综合 | 实现 | 合计 |
|---|---|---|---|---|
| 最大线程32,使用线程32-MB-1 | 3m07s | 26s | 4m28s | 8m01s |
| 最大线程32,使用线程32-MB-2 | 3m08s | 26s | 4m27s | 8m01s |
| 最大线程32,使用线程32-MB-平均 | 3m07.5s | 26s | 4m27.5s | 8m01s |
ZYNQU
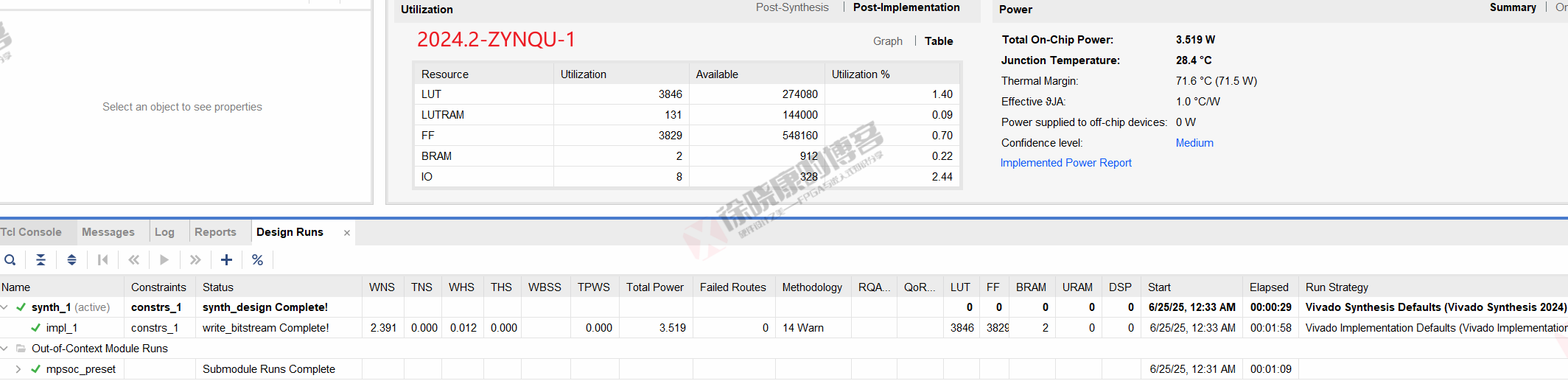
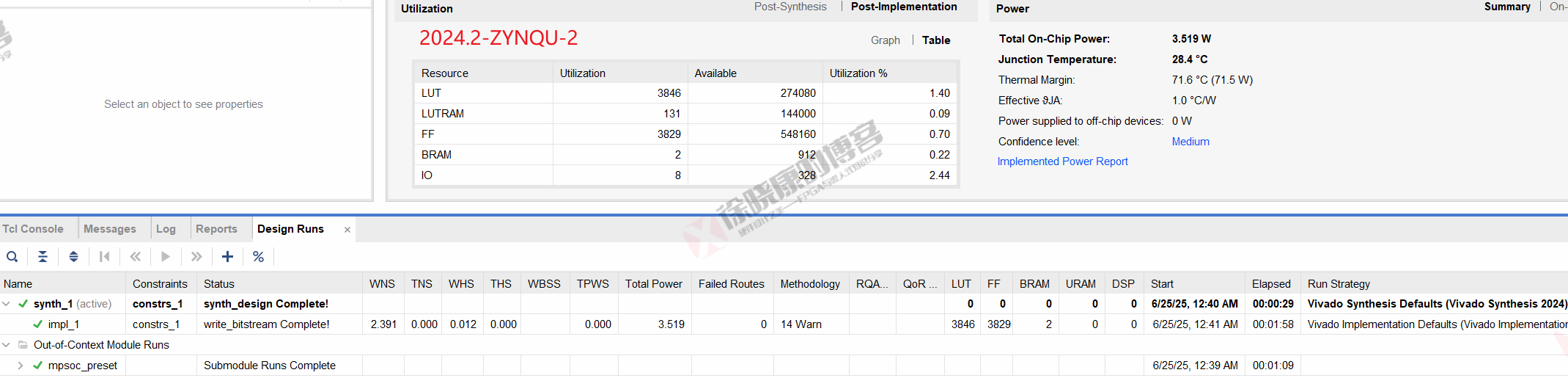
| 实验编号 | OOC | 综合 | 实现 | 合计 |
|---|---|---|---|---|
| 最大线程32,使用线程32-ZYNQU-1 | 1m09s | 29s | 1m58s | 3m36s |
| 最大线程32,使用线程32-ZYNQU-2 | 1m09s | 29s | 1m58s | 3m36s |
| 最大线程32,使用线程32-ZYNQU-平均 | 1m09s | 29s | 1m58s | 3m36s |
2.3 最大线程32,使用线程16
CPU
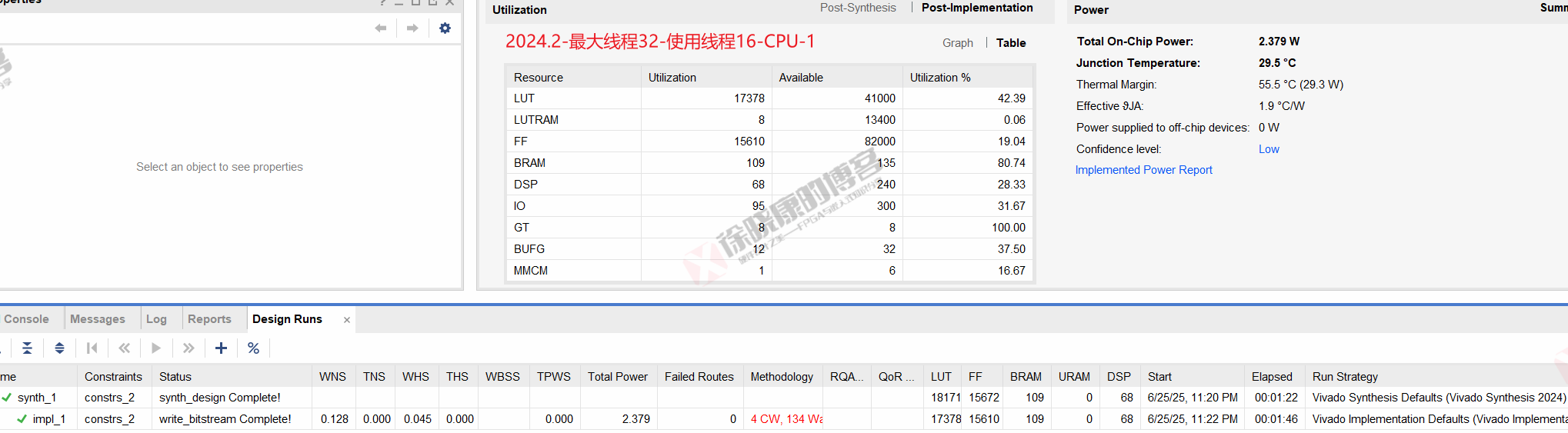
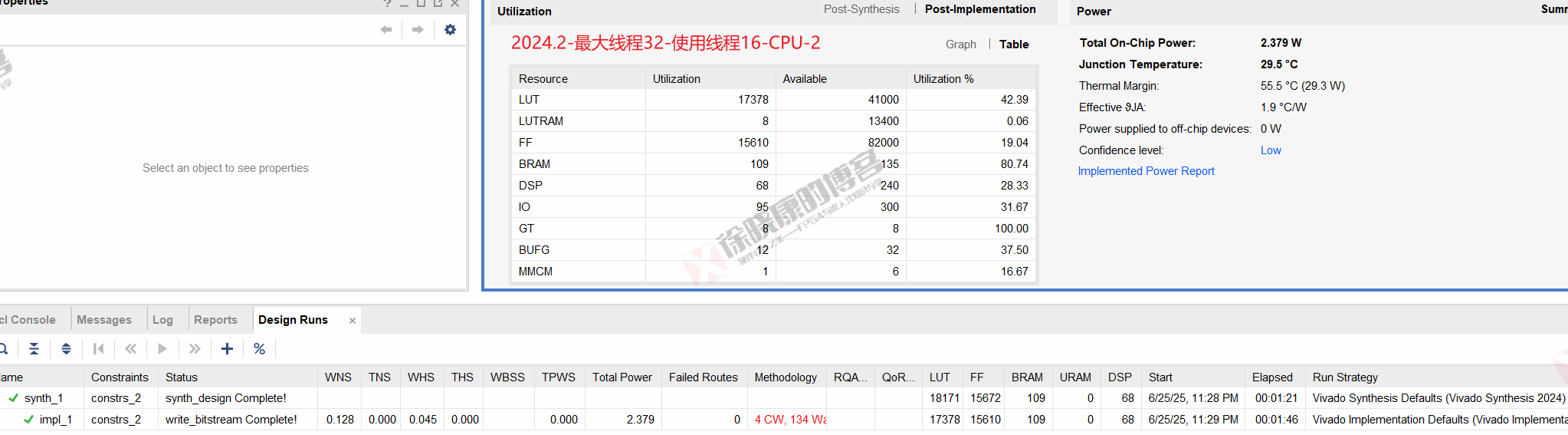
| 实验编号 | OOC | 综合 | 实现 | 合计 |
|---|---|---|---|---|
| 最大线程32,使用线程16-CPU-1 | 0 | 1m22s | 1m46s | 3m08s |
| 最大线程32,使用线程16-CPU-2 | 0 | 1m21s | 1m46s | 3m07s |
| 最大线程32,使用线程16-CPU-平均 | 0 | 1m21.5s | 1m46s | 3m07.5s |
MB
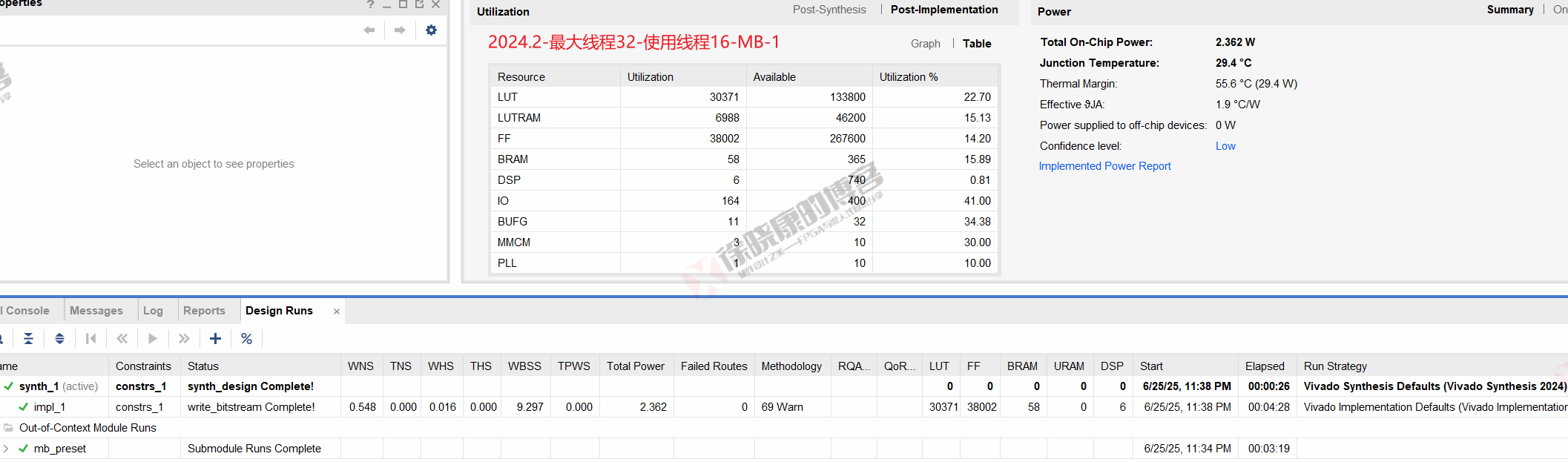
| 实验编号 | OOC | 综合 | 实现 | 合计 |
|---|---|---|---|---|
| 最大线程32,使用线程16-MB-1 | 3m19s | 26s | 4m28s | 8m13s |
| 最大线程32,使用线程16-MB-2 | 3m21s | 26s | 4m27s | 8m14s |
| 最大线程32,使用线程16-MB-平均 | 3m20s | 26s | 4m27.5s | 8m13.5s |
ZYNQU
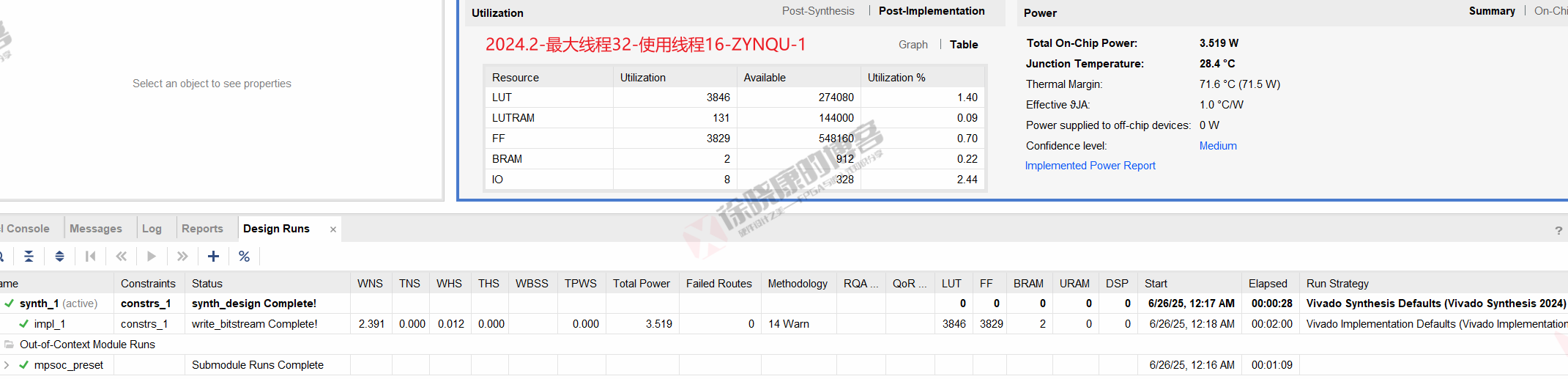
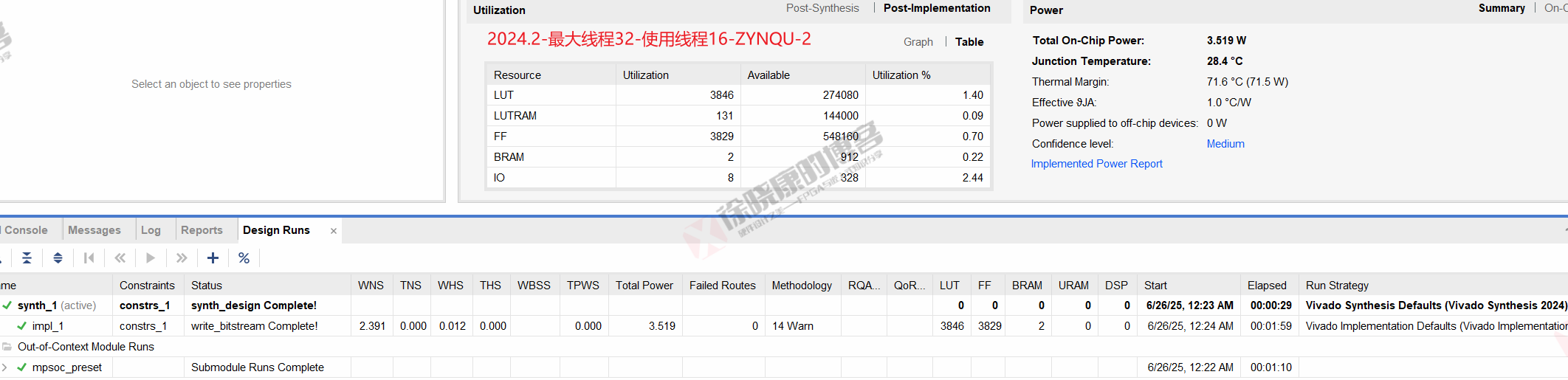
| 实验编号 | OOC | 综合 | 实现 | 合计 |
|---|---|---|---|---|
| 最大线程32,使用线程16-ZYNQU-1 | 1m09s | 28s | 2m00s | 3m37s |
| 最大线程32,使用线程16-ZYNQU-2 | 1m10s | 29s | 1m59s | 3m38s |
| 最大线程32,使用线程16-ZYNQU-平均 | 1m09.5s | 28.5s | 1m59.5s | 3m37.5s |
2.4 最大线程32,使用线程8
CPU
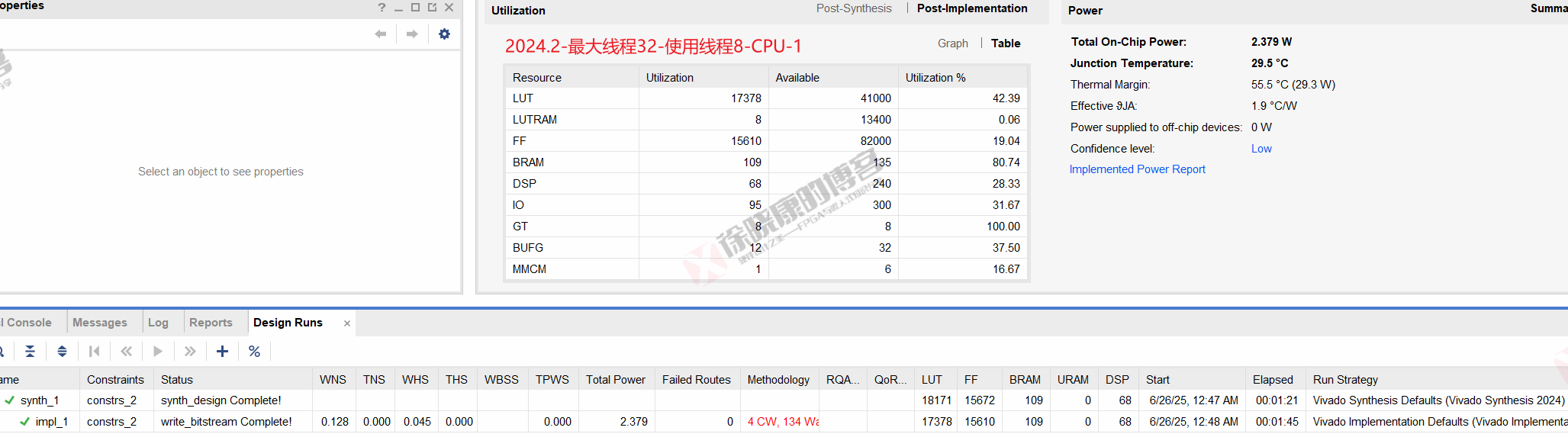
| 实验编号 | OOC | 综合 | 实现 | 合计 |
|---|---|---|---|---|
| 最大线程32,使用线程8-CPU-1 | 0 | 1m21s | 1m45s | 3m06s |
| 最大线程32,使用线程8-CPU-2 | 0 | 1m21s | 1m46s | 3m07s |
| 最大线程32,使用线程8-CPU-平均 | 0 | 1m21s | 1m45.5s | 3m06.5s |
MB
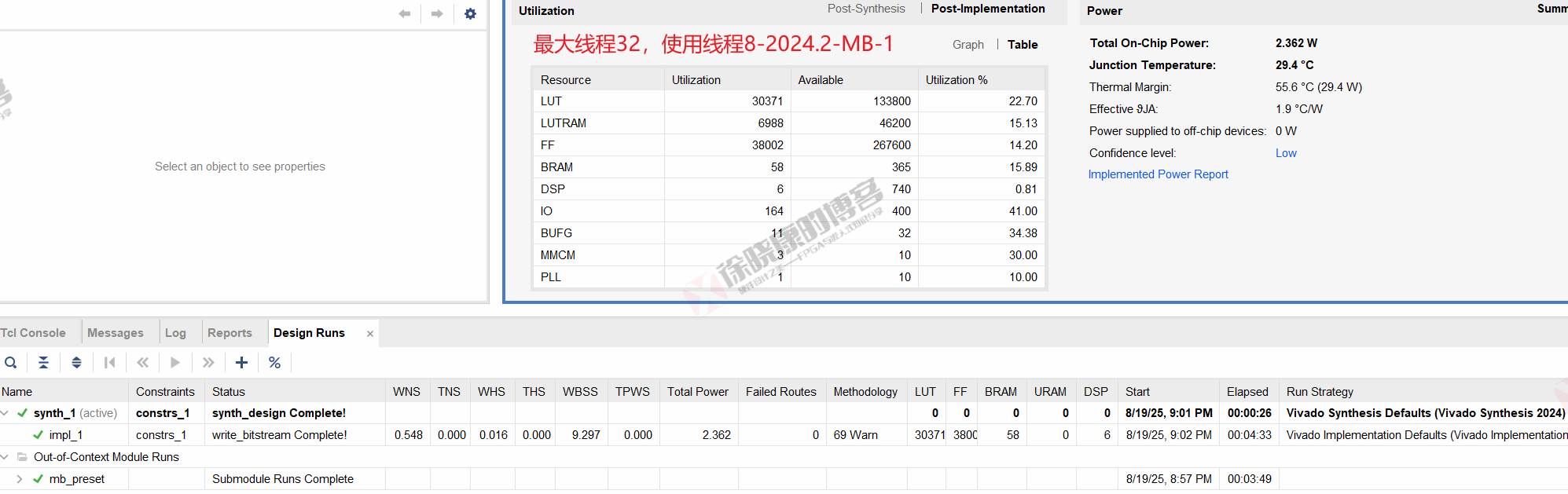
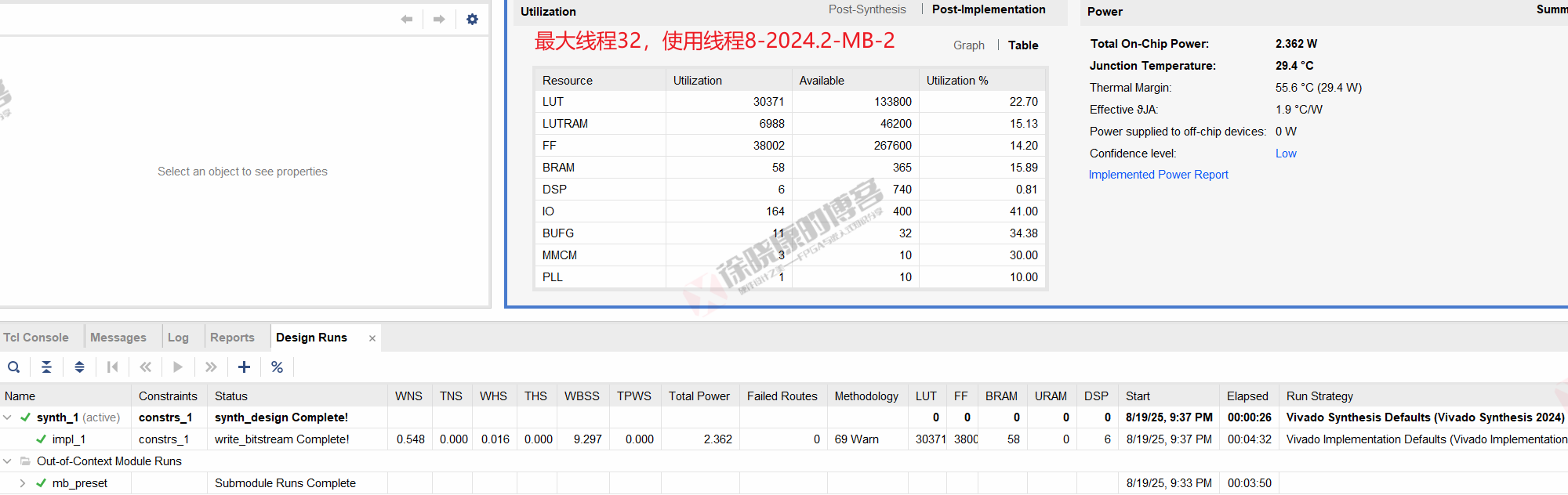
| 实验编号 | OOC | 综合 | 实现 | 合计 |
|---|---|---|---|---|
| 最大线程32,使用线程8-MB-1 | 3m49s | 26s | 4m32s | 8m47s |
| 最大线程32,使用线程8-MB-2 | 3m50s | 26s | 4m32s | 8m48s |
| 最大线程32,使用线程8-MB-平均 | 3m49.5s | 26s | 4m32s | 8m47.5s |
ZYNQU
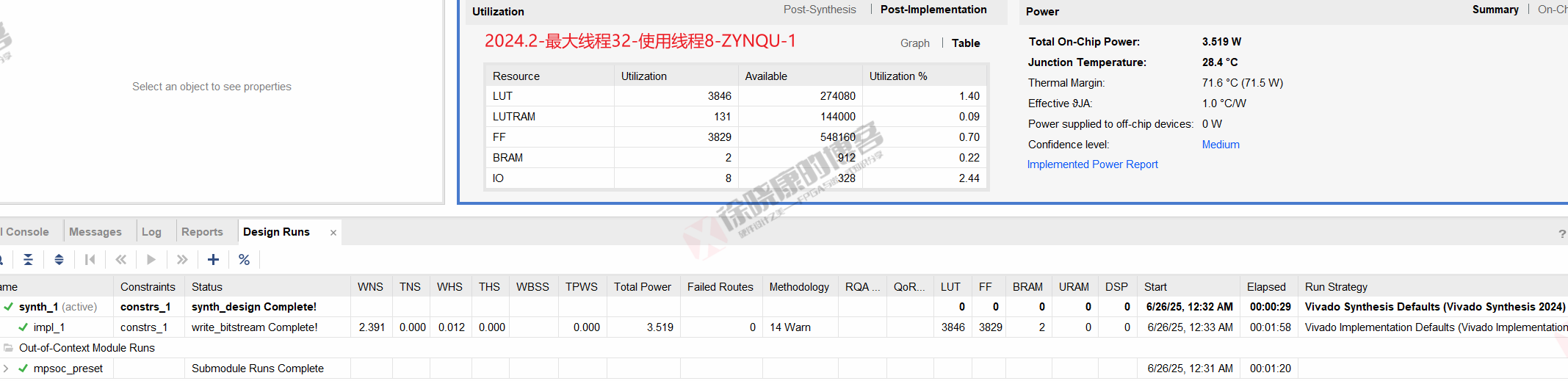
| 实验编号 | OOC | 综合 | 实现 | 合计 |
|---|---|---|---|---|
| 最大线程32,使用线程8-ZYNQU-1 | 1m20s | 29s | 1m58s | 3m47s |
| 最大线程32,使用线程8-ZYNQU-2 | 1m19s | 29s | 1m58s | 3m46s |
| 最大线程32,使用线程8-ZYNQU-平均 | 1m19.5s | 29s | 1m58s | 3m46.5s |
2.5 最大线程32,使用线程4
CPU
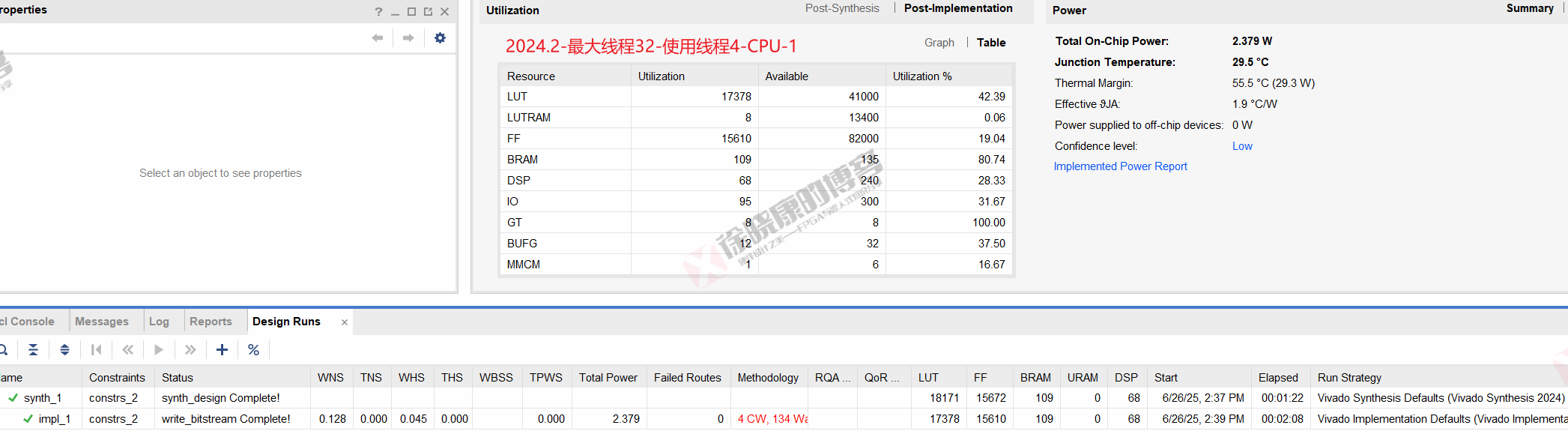
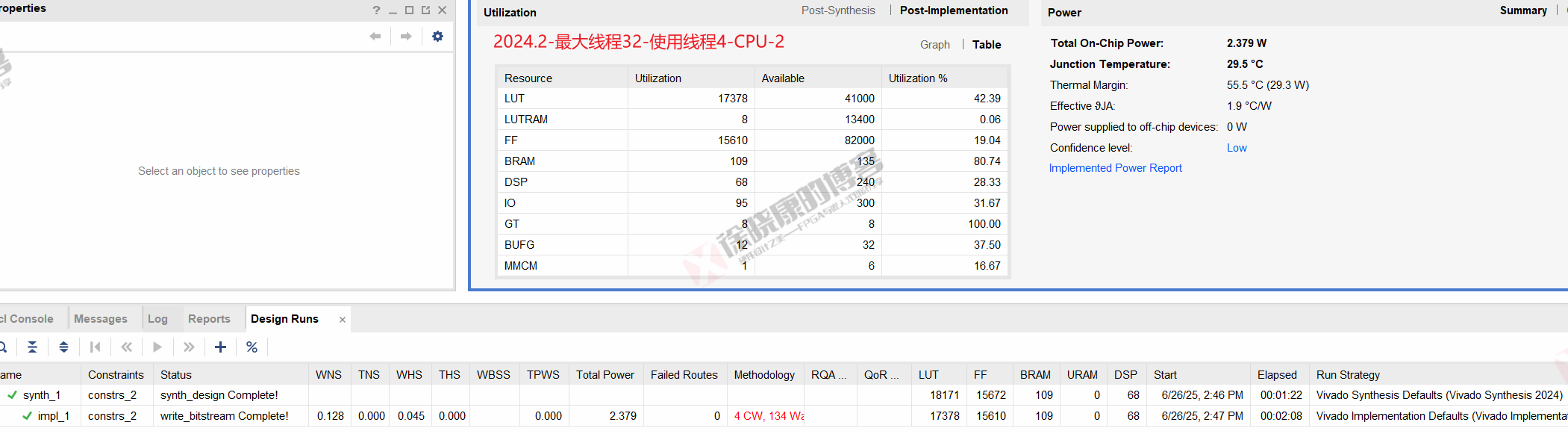
| 实验编号 | OOC | 综合 | 实现 | 合计 |
|---|---|---|---|---|
| 最大线程32,使用线程4-CPU-1 | 0 | 1m22s | 2m08s | 3m30s |
| 最大线程32,使用线程4-CPU-2 | 0 | 1m22s | 2m08s | 3m30s |
| 最大线程32,使用线程4-CPU-平均 | 0 | 1m22s | 2m08s | 3m30s |
MB
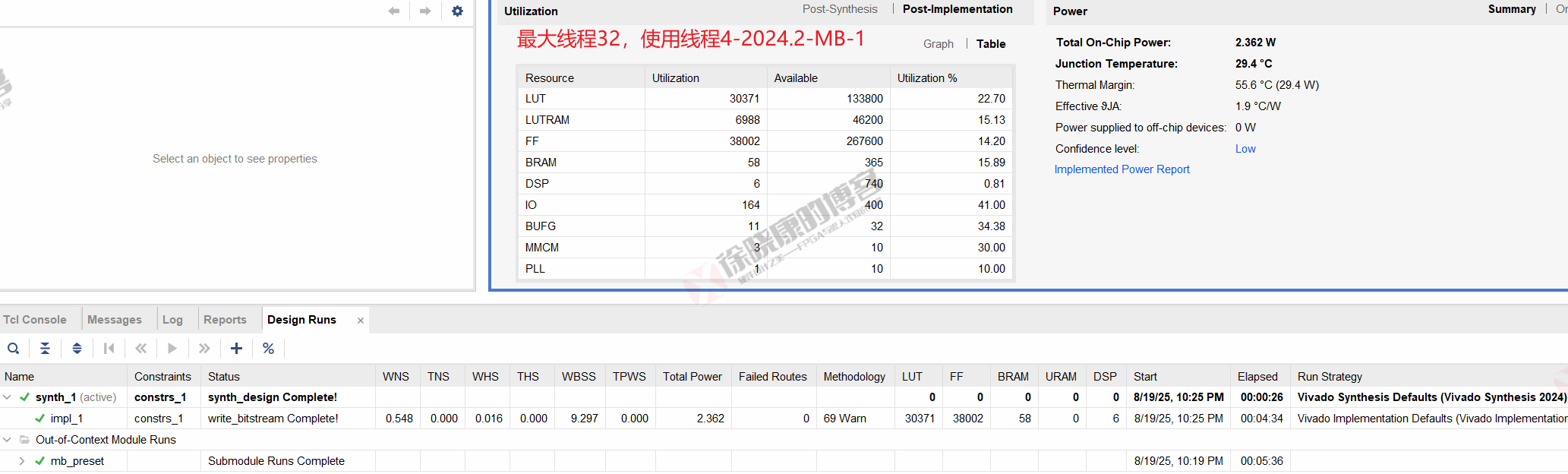
| 实验编号 | OOC | 综合 | 实现 | 合计 |
|---|---|---|---|---|
| 最大线程32,使用线程4-MB-1 | 5m36s | 26s | 4m34s | 10m36s |
| 最大线程32,使用线程4-MB-2 | 5m37s | 27s | 4m33s | 10m37s |
| 最大线程32,使用线程4-MB-平均 | 5m36.5s | 26.5s | 4m33.5s | 10m36.5s |
ZYNQU
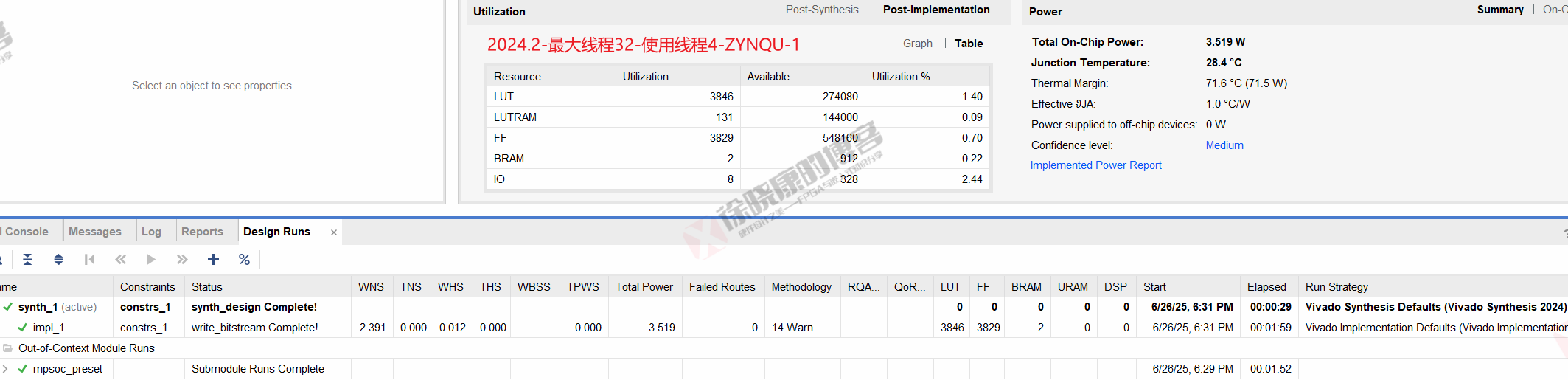
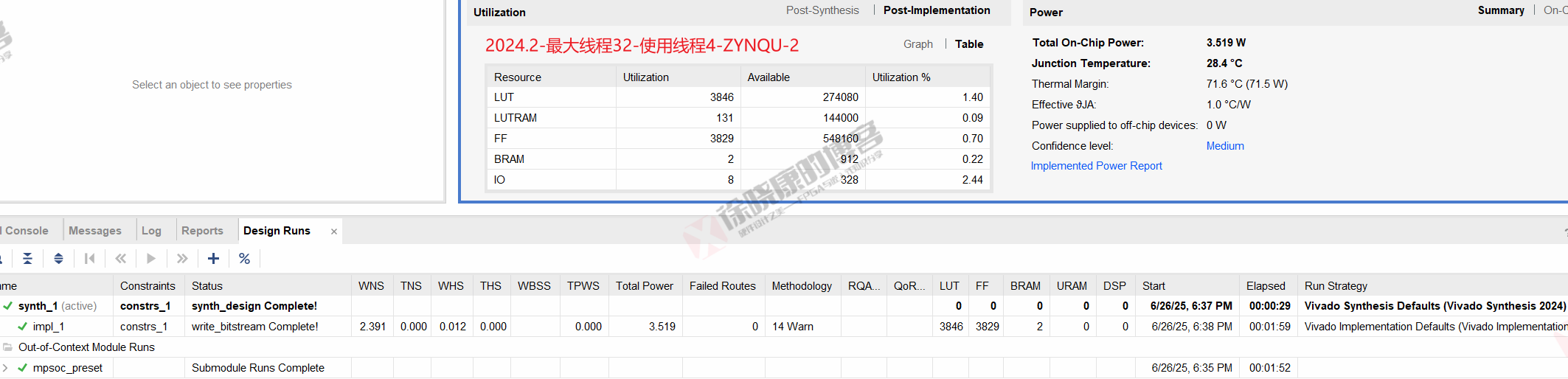
| 实验编号 | OOC | 综合 | 实现 | 合计 |
|---|---|---|---|---|
| 最大线程32,使用线程4-ZYNQU-1 | 1m52s | 29s | 1m59s | 4m20s |
| 最大线程32,使用线程4-ZYNQU-2 | 1m52s | 29s | 1m59s | 4m20s |
| 最大线程32,使用线程4-ZYNQU-平均 | 1m52s | 29s | 1m59s | 4m20s |
三、实验结果统计与分析
| 实验条件/平均编译时间/示例工程 | CPU | MB | ZYNQU |
|---|---|---|---|
| 最大线程2,使用线程32 | 3m28s (+10.1%) | 8m37s (+7.5%) | 3m47s (+5.1%) |
| 最大线程32,使用线程32 | 3m09s | 8m01s | 3m36s |
| 最大线程32,使用线程16 | 3m07.5s (-0.8%) | 8m13.5s (+2.6%) | 3m37.5s (+0.7%) |
| 最大线程32,使用线程8 | 3m06.5s (-1.3%) | 8m47.5s (+9.7%) | 3m46.5s (+4.9%) |
| 最大线程32,使用线程4 | 3m30s (+11.1%) | 10m36.5s (+32.3%) | 4m20s (+20.4%) |
基于以上表格数据进行分析,可以得到如下结论:
-
最大线程设置有用,设置成2确实拖慢了Vivado编译速度,所以, 必须把最大线程设到最大值32并设置成Vivado启动自动设置; -
使用线程对Vivado编译速度同样有影响, 应该设置成CPU最大线程; -
Vivado最多能利用的线程数应该是16,可以发现使用线程32和16,两者编译时间几乎没区别。
本文测试结果仅供参考。
四、测试工程分享
本系列文章的所有测试工程,如下图所示。
均通过网盘分享。
欢迎大家关注我的微信公众号:徐晓康的博客,回复以下6位数字获取网盘链接。
981520
建议复制过去不会码错字!
如果本文对你有所帮助,欢迎点赞、转发、收藏、评论让更多人看到,赞赏支持就更好了。
如果对文章内容有疑问,请务必清楚描述问题,留言评论或私信告知我,我看到会回复。

徐晓康的博客持续分享高质量硬件、FPGA与嵌入式知识,软件,工具等内容,欢迎大家关注。