

前言
书接上文,本文测试Vivado的两种非GUI模式即Tcl-Project Mode和Tcl-Non-Project Mode能否提高编译速度。
先说结论,测试结果表明:两种模式均无法提升编译速度,甚至更慢。
一、实验条件说明
-
同前文一样,使用CPU、MB和ZYNQU作为测试工程; -
Vivado版本为2024.2; -
GUI模式使用之前已经测得的数据; -
非GUI模式即用Tcl命令进行编译,测试条件分为两种: -
Tcl-Project Mode,即用Tcl命令在Project Mode下编译文件; -
Tcl-Non-Project Mode,即用Tcl命令在Non-Project Mode下编译文件。
-
二、如何使用Tcl-Project Mode进行编译
关于Vivado的tcl命令可参考:ug835-vivado-tcl-commands-en-us-2024.2.pdf

2.1 Tcl命令行工具
有两种tcl命令行工具可用:
-
使用Vivado软件自带的命令行工具-Vivado 2024.2 Tcl Shell;
-
使用Windows系统的命令行工具-Windows PowerShell。
2.2 如何使用Vivado Tcl Shell
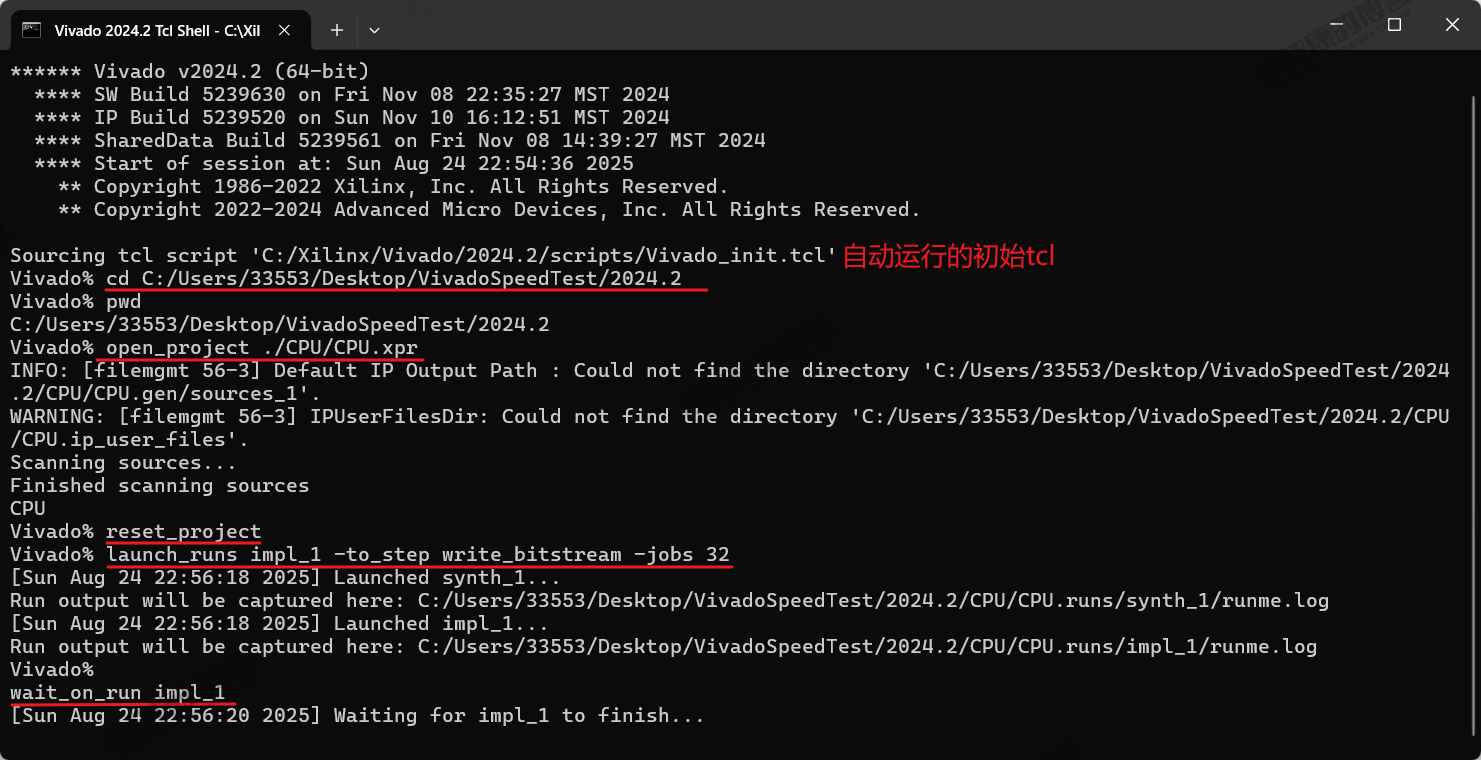
切换目录:注意这个/,是除号。
cd C:/Users/33553/Desktop/VivadoSpeedTest/2024.2/CPU
确认当前目录:
pwd
打开工程:
open_project CPU.xpr
复位工程:
reset_project
开始编译:生成bit流,使用32线程
launch_runs impl_1 -to_step write_bitstream -jobs 32
等待编译完成:
wait_on_run impl_1
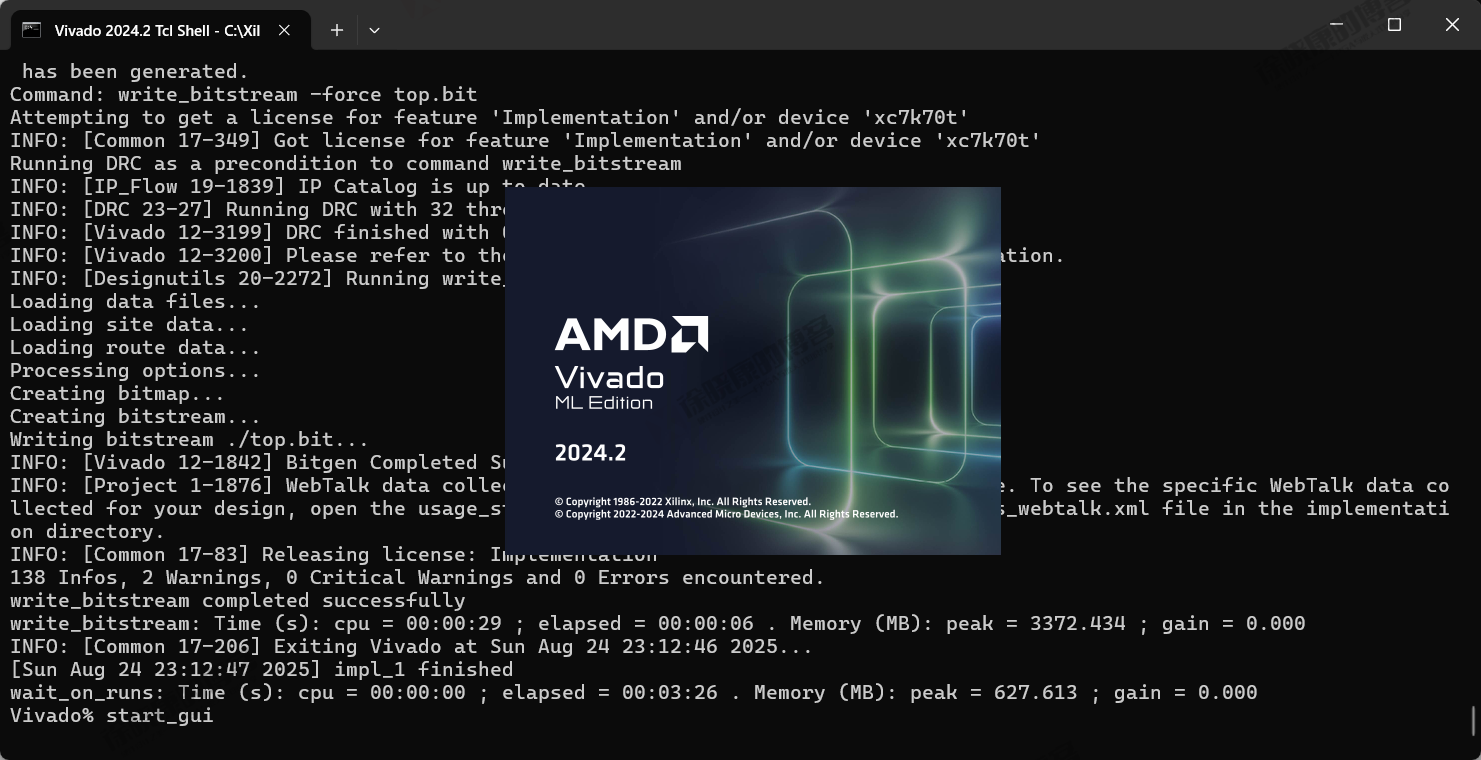
编译完成之后可以打开GUI:
start_gui
在Vivado Tcl Shell中使用这些命令的示意如下图所示。
更简单的方式是将上述指令都写入一个tcl文件,然后直接运行此tcl文件即可,如:
# @Author : Xu Xiaokang
# @Date : 2025-08-28 21:08:12
# Project Mode generate bitstream
# run in vivado 2024.2 Tcl Shell
# source "C:/_myJGY/17_Markdown/Vivado/Tcl-Project Mode/ProjectMode.tcl"
# 设置工程名称
set project_name CPU
set project_folder_name $project_name
# 设置准确的工程文件路径
set project_path "C:/Users/33553/Desktop/VivadoSpeedTest/2024.2/$project_folder_name/$project_name"
# 打开工程
open_project $project_path
# 复位工程
reset_project
# 生成bit流
launch_runs impl_1 -to_step write_bitstream -jobs 32
wait_on_run impl_1
# 打开gui
start_gui
2.3 如何使用PowerShell
首先将vivado.exe的路径(如C:\Xilinx\Vivado\2024.2\bin)添加到用户环境变量PATH中:
或者,使用以下命令在PowerShell窗口中临时添加环境变量。
$env:PATH += ";C:\Xilinx\Vivado\2024.2\bin"
然后,运行tcl脚本即可。
-
使用交互式的tcl进行运行
vivado -mode tcl -source "C:/_myJGY/17_Markdown/Vivado/Tcl-Project Mode/ProjectMode.tcl"
-
使用批处理命令运行
vivado -mode batch -source "C:/_myJGY/17_Markdown/Vivado/Tcl-Project Mode/ProjectMode.tcl"
两种命令都是调用Vivado Tcl Shell运行tcl文件,暂未发现两者的区别,此处任选一种即可。
三、使用Tcl-Non-Project Mode进行编译
Non-Project Mode下不会自动生成报告,所以,为保证测试的公平性,这里希望非工程模式和工程模式生成一样的报告,这样比较编译速度才有意义。
3.1 Vivado默认报告策略生成的报告
Vivado默认报告策略下的Reports界面,如下图所示。
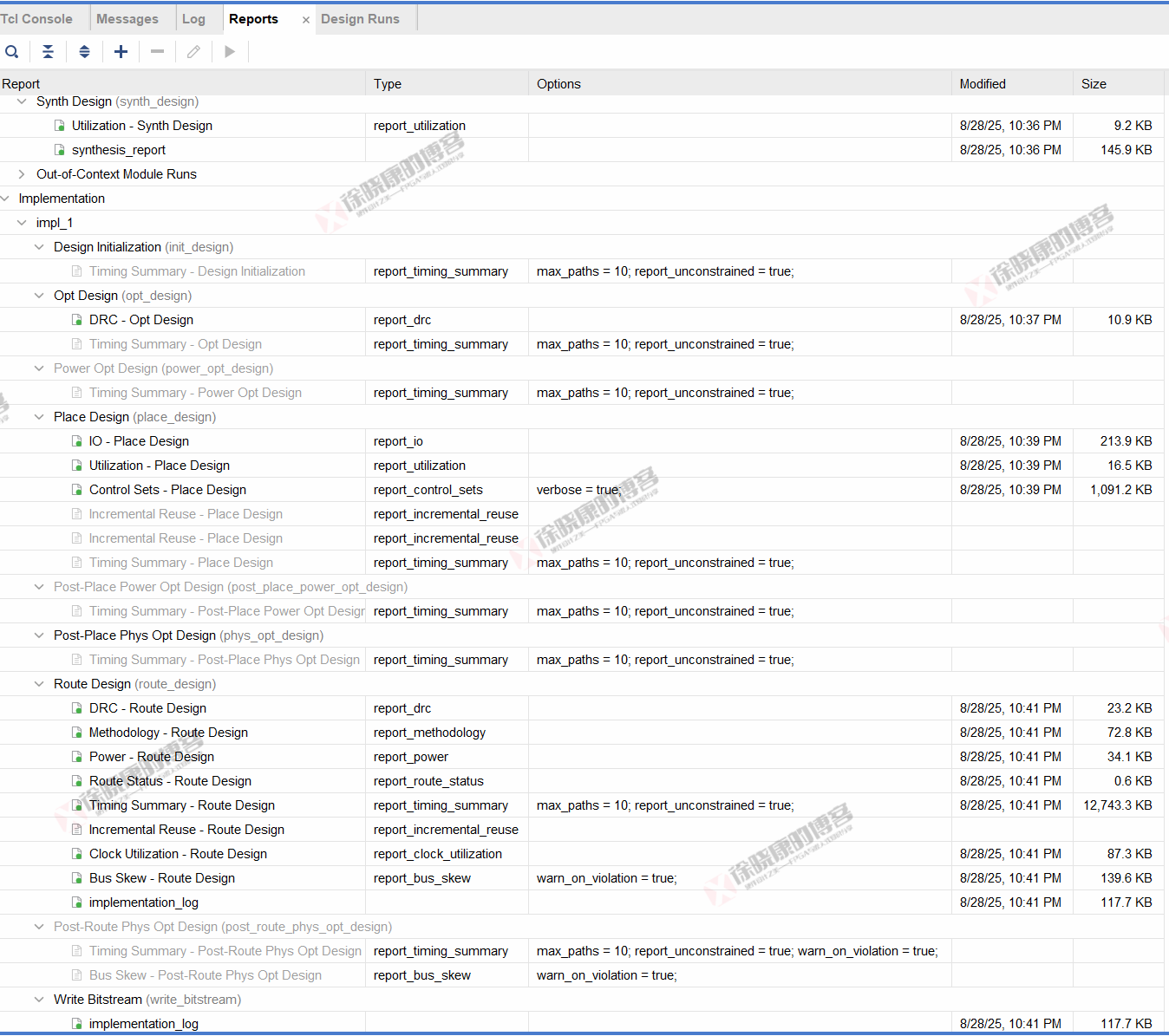
灰色的是默认编译策略没有执行的编译步骤,以及默认报告策略没有生成的报告。上图整理成表格:
| 序号 | 阶段 | 默认编译策略 | Report | Type | Options | 默认报告策略 |
|---|---|---|---|---|---|---|
| 1.1 | 综合– Synth Design |
是 | Utilization – Synth Design | report_utilization | 是 | |
| 1.2 | Synthesis Report | 是 | ||||
| 0.1 | 综合– Out-of-Context Module Runs |
是 | xx–Utilization – Synth Design | report_utilization | 是 | |
| 0.2 | xx-Synthesis Report | 是 | ||||
| 2.1 | 实现– Design Initialization (init_design) |
是 | Timing Summary – Design Initialization | report_timing_summary | max_paths = 10, report_unconstrained = true; | 否 |
| 2.2 | 实现– Opt Design (opt_design) |
是 | DRC – Opt Design | report_drc | 是 | |
| Timing Summary – Opt Design | report_timing_summary | max_paths = 10, report_unconstrained = true; |
否 | |||
| 2.3 | 实现– Power Opt Design (power_opt_design) |
否 | Timing Summary – Power Opt Design | report_timing_summary | max_paths = 10, report_unconstrained = true; |
否 |
| 2.4 | 实现– Place Design (place_design) |
是 | IO – Place Design | report_io | 是 | |
| Utilization – Place Design | report_utilization | 是 | ||||
| Control Sets – Place Design | report_control_sets | verbose = true; | 是 | |||
| Incremental Reuse – Place Design | report_incremental_reuse | 否 | ||||
| Timing Summary – Place Design | report_timing_summary | max_paths = 10, report_unconstrained = true; |
否 | |||
| 2.5 | 实现– Post – Place Power Opt Design (post_place_power_opt_design) |
否 | Timing Summary – Post – Place Power Opt Design | report_timing_summary | max_paths = 10, report_unconstrained = true; |
否 |
| 2.6 | 实现– Post – Place Phys Opt Design (phys_opt_design) |
是 | Timing Summary – Post – Place Phys Opt Design | report_timing_summary | max_paths = 10, report_unconstrained = true; |
否 |
| 2.7 | 实现– Route Design (route_design) |
是 | DRC – Route Design | report_drc | 是 | |
| Methodology – Route Design | report_methodology | 是 | ||||
| Power – Route Design | report_power | 是 | ||||
| Route Status – Route Design | report_route_status | 是 | ||||
| Timing Summary – Route Design | report_timing_summary | max_paths = 10, report_unconstrained = true; |
是 | |||
| Incremental Reuse – Route Design | report_incremental_reuse | 否 | ||||
| Clock Utilization – Route Design | report_clock_utilization | 是 | ||||
| Bus Skew – Route Design | report_bus_skew | warn_on_violation = true; | 是 | |||
| implementation log | 是 | |||||
| 2.8 | 实现– Post – Route Phys Opt Design (post_route_phys_opt_design) |
否 | Timing Summary – Post – Route Phys Opt Design | report_timing_summary | max_paths = 10, report_unconstrained = true, warn_on_violation = true; |
否 |
| Bus Skew – Post – Route Phys Opt Design | report_bus_skew | warn_on_violation = true; | 否 | |||
| 2.9 | 实现– Write Bitstream (Write Bitstream) |
是 | implementation log | 是 |
这些报告的功能如下表:
| 序号 | 报告名称 | 类别 | 功能描述 |
|---|---|---|---|
| 1.1 | 资源利用率报告 | 资源分析 | 展示设计在目标器件上的逻辑资源(如LUT、FF、BRAM、DSP等)使用情况。 |
| 1.2 | 综合报告 | 综合总结 | 提供综合过程的概要信息,包括警告、错误、优化结果等。 |
| 0.1 | xx-资源利用率报告 | 资源分析 | 展示Out-of-Context模块综合后的逻辑资源使用情况。 |
| 0.2 | xx-综合报告 | 综合总结 | 提供Out-of-Context模块综合过程的概要信息。 |
| 2.1 | 时序概要报告 | 时序分析 | 设计初始化后的时序概览,报告最差路径(默认10条)和未约束路径的时序情况。 |
| 2.2 | DRC 报告 | 设计规则检查 | 检查设计是否违反任何设计规则(如逻辑连接性、时钟有效性等)。 |
| 时序概要报告 | 时序分析 | 逻辑优化后的时序概览,报告最差路径和未约束路径的时序情况。 | |
| 2.3 | 时序概要报告 | 时序分析 | 功耗优化后的时序概览,报告最差路径和未约束路径的时序情况。 |
| 2.4 | I/O 报告 | I/O 分析 | 显示器件 I/O 引脚的使用和配置情况。 |
| 资源利用率报告 | 资源分析 | 布局后的逻辑资源使用情况。 | |
| 控制集报告 | 时钟域分析 | 详细报告设计中的时钟控制集(如时钟使能、同步/异步复位)的使用和分布。 | |
| 增量重用报告 | 增量编译 | 报告在增量编译中模块复用的情况。 | |
| 时序概要报告 | 时序分析 | 布局后的时序概览,报告最差路径和未约束路径的时序情况。 | |
| 2.5 | 时序概要报告 | 时序分析 | 布局后功耗优化阶段的时序概览。 |
| 2.6 | 时序概要报告 | 时序分析 | 布局后物理优化阶段的时序概览。 |
| 2.7 | DRC 报告 | 设计规则检查 | 布线后的设计规则检查,确保布线结果满足电气和物理规则。 |
| 方法论报告 | 设计规则检查 | 检查设计是否符合推荐的设计方法论(如 UltraFast 方法学)。 | |
| 功耗报告 | 功耗分析 | 估算设计在布线后的动态和静态功耗。 | |
| 布线状态报告 | 布线状态 | 提供布线的完成状态和结果信息(如是否完全布线、有无布线错误)。 | |
| 时序概要报告 | 时序分析 | ** 最终布线后的时序总结 **,报告建立时间/保持时间裕量、最差路径等。 | |
| 增量重用报告 | 增量编译 | 报告布线后增量编译模块的复用情况。 | |
| 时钟利用率报告 | 时钟分析 | 显示时钟网络上的负载和资源使用情况。 | |
| 总线偏斜报告 | 时序分析 | 报告总线中各位信号之间的时序偏斜(Skew),检查是否违反约束。 | |
| 实现日志 | 流程总结 | 记录整个实现过程的日志文件,包含所有步骤的详细输出、警告和错误。 | |
| 2.8 | 时序概要报告 | 时序分析 | 布线后物理优化阶段的时序概览。 |
| 总线偏斜报告 | 时序分析 | 布线后物理优化后的总线偏斜情况。 | |
| 2.9 | 实现日志 | 流程总结 | 记录比特流生成过程的日志信息。 |
3.2 Non-Project Mode的编译流程与Tcl命令
关于Project Mode和Non-Project Mode的区别可参考官方文档:ug892-vivado-design-flows-overview-en-us-2024.2.pdf
Non-Project 模式的设计步骤和核心 Tcl 命令:
| 阶段 | 核心 Tcl 命令 (括号内为常用可选项示例) | 主要功能描述 |
|---|---|---|
| 准备工作 | set outputDir ./your_dir file mkdir $outputDir | 设置输出目录并创建 |
| 读取设计文件 | read_verilog read_vhdl read_xdc read_edif read_checkpoint | 读取 Verilog / VHDL 设计文件、XDC 约束文件、EDIF/NGC 网表或已有的 DCP 检查点文件 |
| 综合 | synth_design (-top <top_name> -part <part_name>) | 将 RTL 综合成门级网表,指定顶层模块和目标器件型号 |
| 实现 | opt_design | 对综合后的设计进行逻辑优化 |
| place_design | 进行布局规划,将逻辑单元放置到器件上的特定位置 | |
| phys_opt_design | (可选) 进行物理优化,改善时序或布线能力 | |
| route_design | 对布局后的设计进行布线连接 | |
| 生成比特流 | write_bitstream (-force <file_name>.bit) | 生成 FPGA 配置所需的比特流文件 |
| 保存设计点 | write_checkpoint (-force $outputDir/ |
将综合、实现等各个阶段的设计状态保存为设计检查点(DCP),便于后续分析和增量设计 |
| 生成报告 | report_timing_summary report_utilization report_power report_drc | 生成时序概要、资源利用率、功耗估计和设计规则检查等报告 |
| GUI交互 | start_gui stop_gui | 在任意阶段启动或关闭 Vivado IDE 图形界面,用于可视化分析设计 |
3.3 简单流程示例
一个典型的 Non-Project 模式 Tcl 脚本流程如下:
# 设置输出目录
set outputDir ./outputs
file mkdir $outputDir
# 读取源文件和约束
read_verilog top.v
read_xdc top.xdc
# 综合设计
synth_design -top top -part xc7a100tcsg324-1
write_checkpoint -force $outputDir/post_synth.dcp
report_timing_summary -file $outputDir/post_synth_timing.rpt
report_utilization -file $outputDir/post_synth_util.rpt
# 实现设计(布局布线)
opt_design
place_design
phys_opt_design # 可选物理优化
write_checkpoint -force $outputDir/post_place.dcp
report_timing_summary -file $outputDir/post_place_timing.rpt
route_design
write_checkpoint -force $outputDir/post_route.dcp
report_timing_summary -file $outputDir/post_route_timing.rpt
report_utilization -file $outputDir/post_route_util.rpt
# 生成比特流文件
write_bitstream -force $outputDir/top.bit
本文使用的三个工程的Non-Project-tcl脚本在文末有分享。
四、测试截图
4.1 普通GUI模式
因本系列的前几篇文章都是用的普通GUI模式,所以这里的测试截图与前几篇文中是一样的,这里仅为提高本文的独立性而保留。
CPU
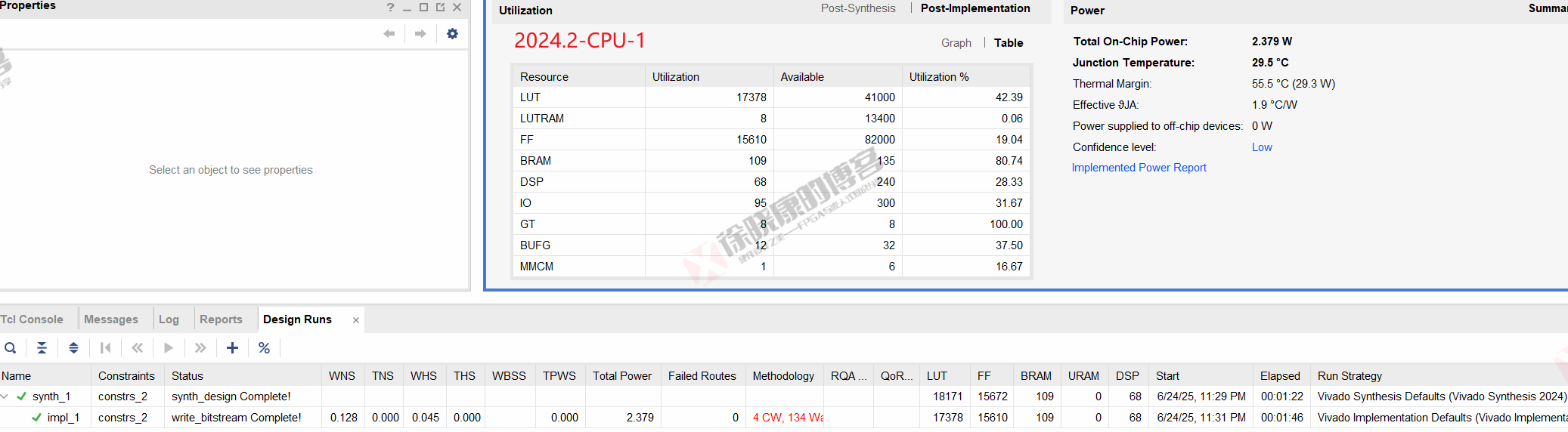
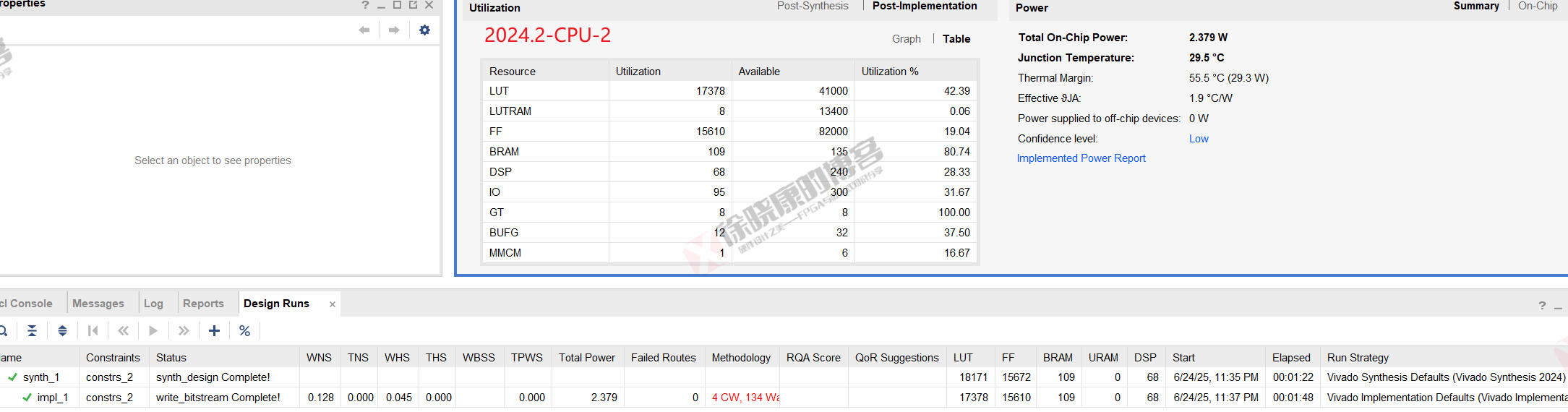
| 实验编号 | OOC | 综合 | 实现 | 合计 |
|---|---|---|---|---|
| 普通GUI模式-CPU-1 | 0 | 1m22s | 1m46s | 3m08s |
| 普通GUI模式-CPU-2 | 0 | 1m22s | 1m48s | 3m10s |
| 普通GUI模式-CPU-平均 | 0 | 1m22s | 1m47s | 3m09s |
MB
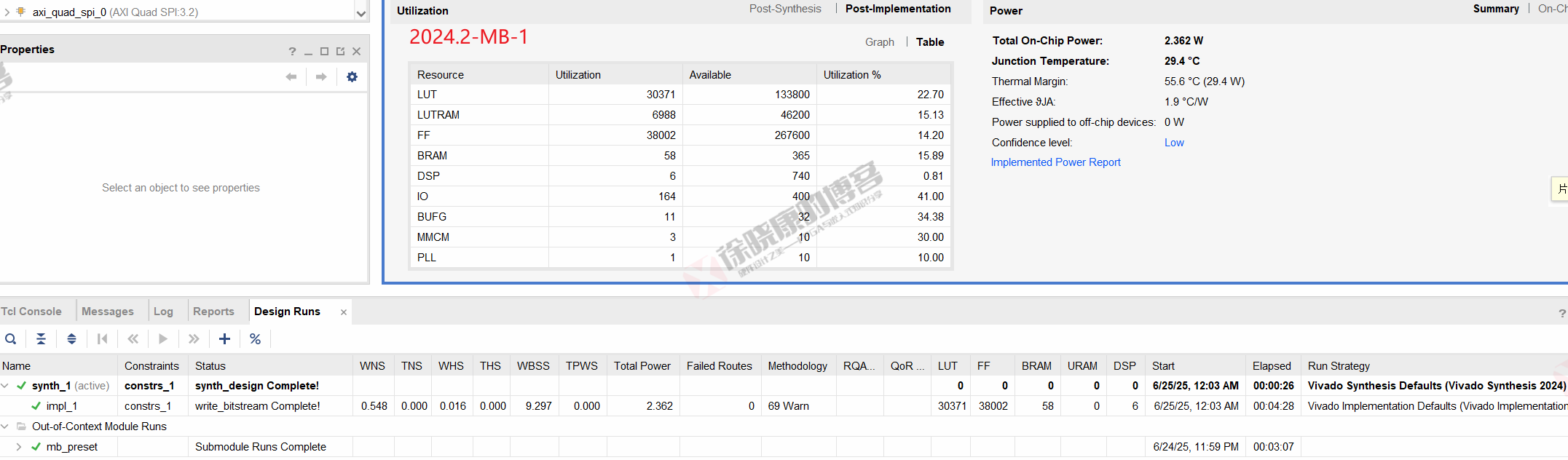
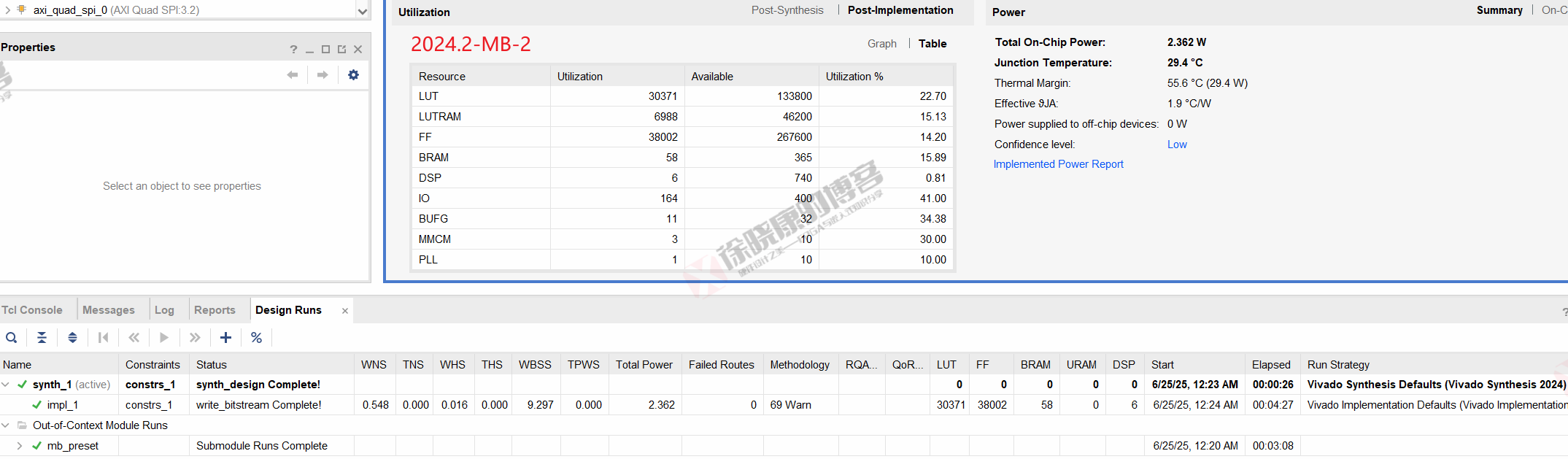
| 实验编号 | OOC | 综合 | 实现 | 合计 |
|---|---|---|---|---|
| 普通GUI模式-MB-1 | 3m07s | 26s | 4m28s | 8m01s |
| 普通GUI模式-MB-2 | 3m08s | 26s | 4m27s | 8m01s |
| 普通GUI模式-MB-平均 | 3m07.5s | 26s | 4m27.5s | 8m01s |
ZYNQU
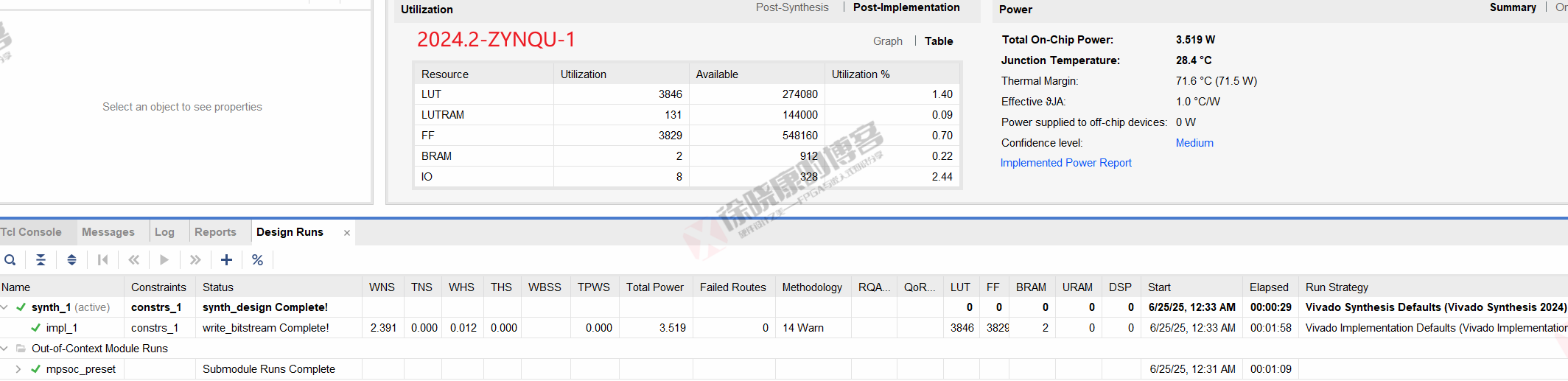
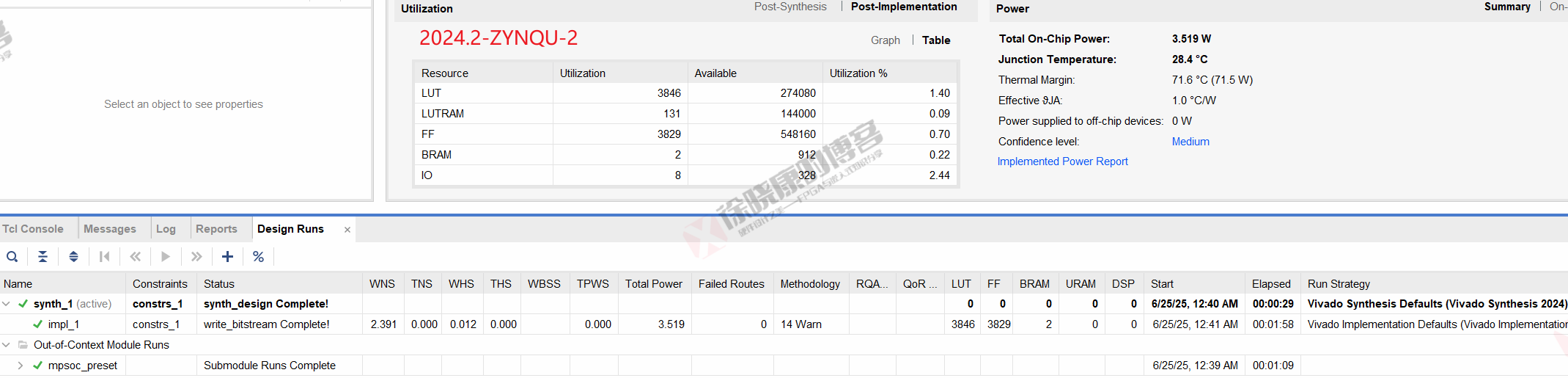
| 实验编号 | OOC | 综合 | 实现 | 合计 |
|---|---|---|---|---|
| 普通GUI模式-ZYNQU-1 | 1m09s | 29s | 1m58s | 3m36s |
| 普通GUI模式-ZYNQU-2 | 1m09s | 29s | 1m58s | 3m36s |
| 普通GUI模式-ZYNQU-平均 | 1m09s | 29s | 1m58s | 3m36s |
4.2 Tcl-Project Mode
CPU
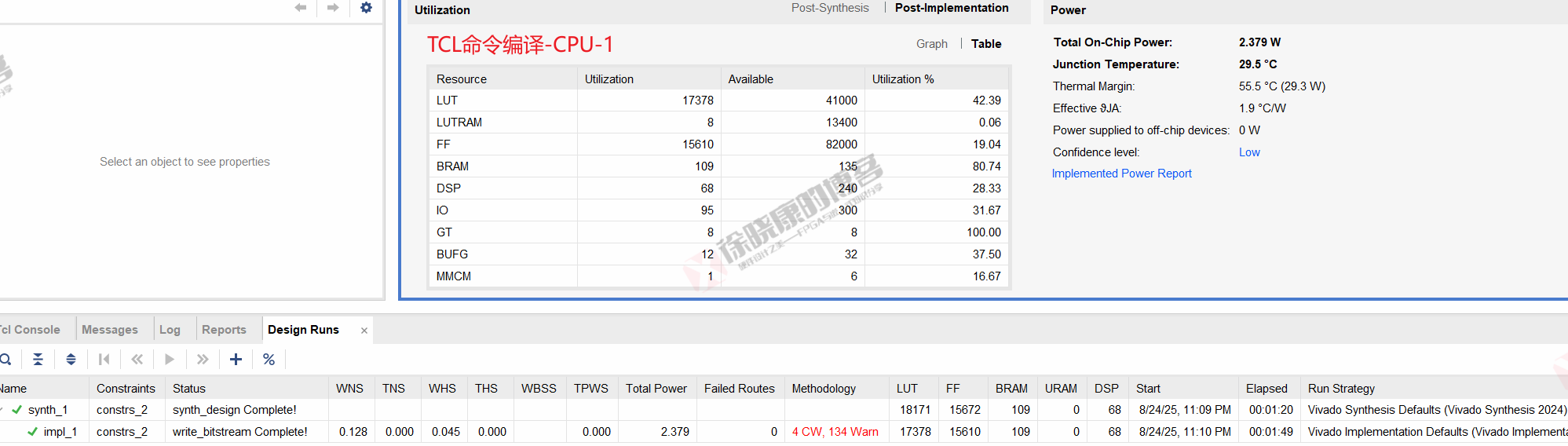
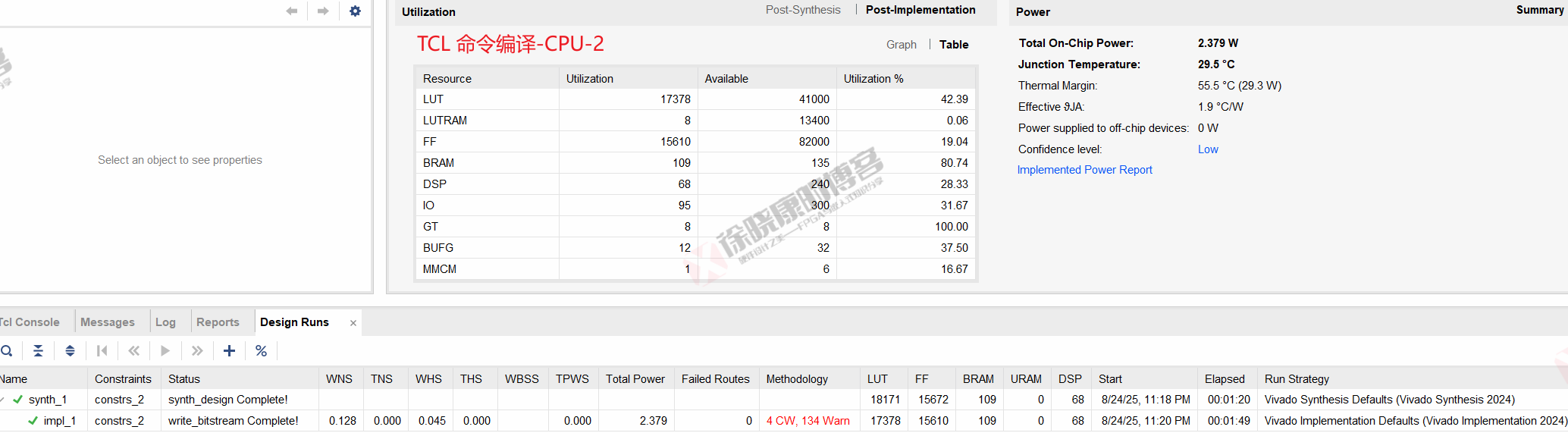
| 实验编号 | OOC | 综合 | 实现 | 合计 |
|---|---|---|---|---|
| Tcl-Project Mode-CPU-1 | 0 | 1m20s | 1m49s | 3m09s |
| Tcl-Project Mode-CPU-2 | 0 | 1m20s | 1m49s | 3m09s |
| Tcl-Project Mode-CPU-平均 | 0 | 1m20s | 1m49s | 3m09s |
MB
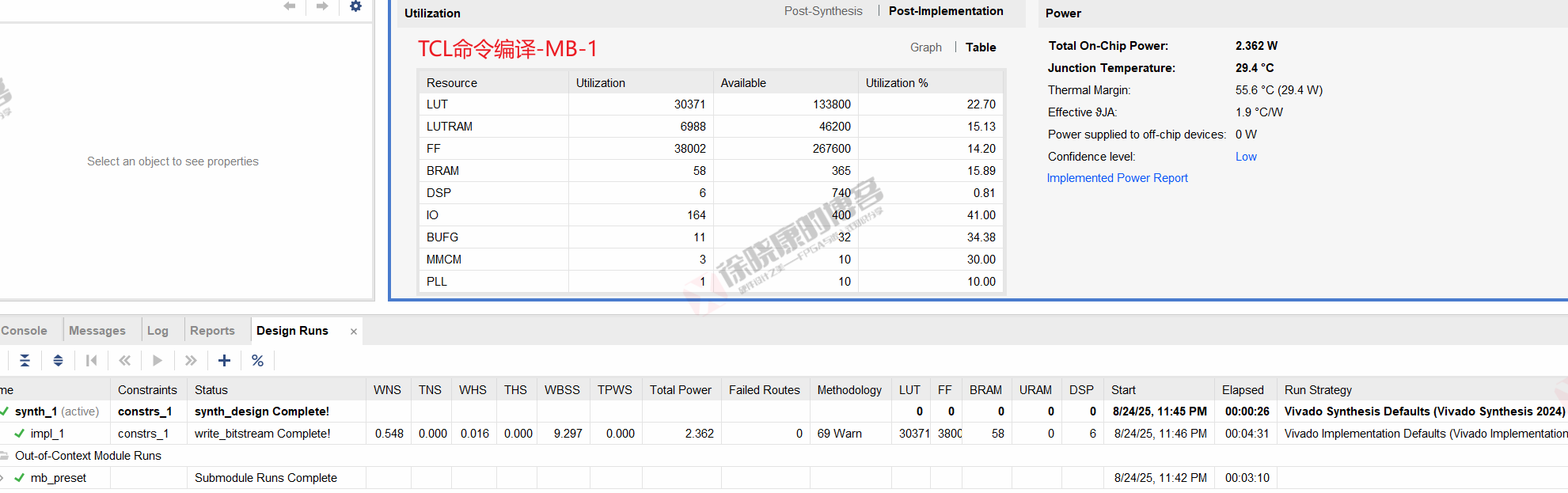
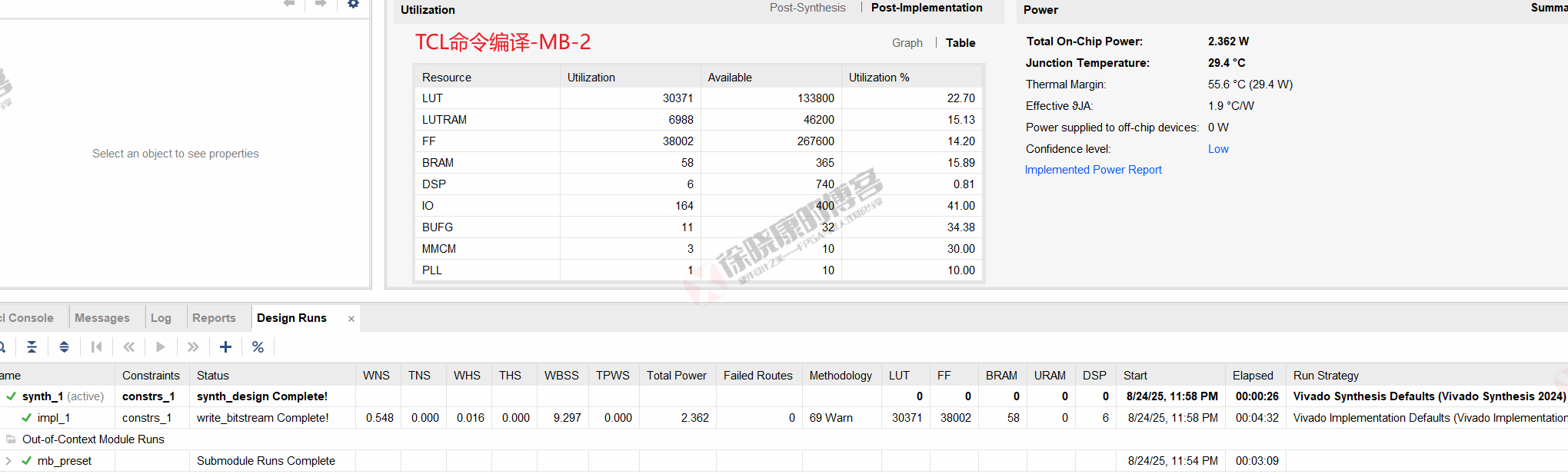
| 实验编号 | OOC | 综合 | 实现 | 合计 |
|---|---|---|---|---|
| Tcl-Project Mode-MB-1 | 3m10s | 26s | 4m31s | 8m07s |
| Tcl-Project Mode-MB-2 | 3m09s | 26s | 4m32s | 8m07s |
| Tcl-Project Mode-MB-平均 | 3m09.5s | 26s | 4m31.5s | 8m07s |
ZYNQU
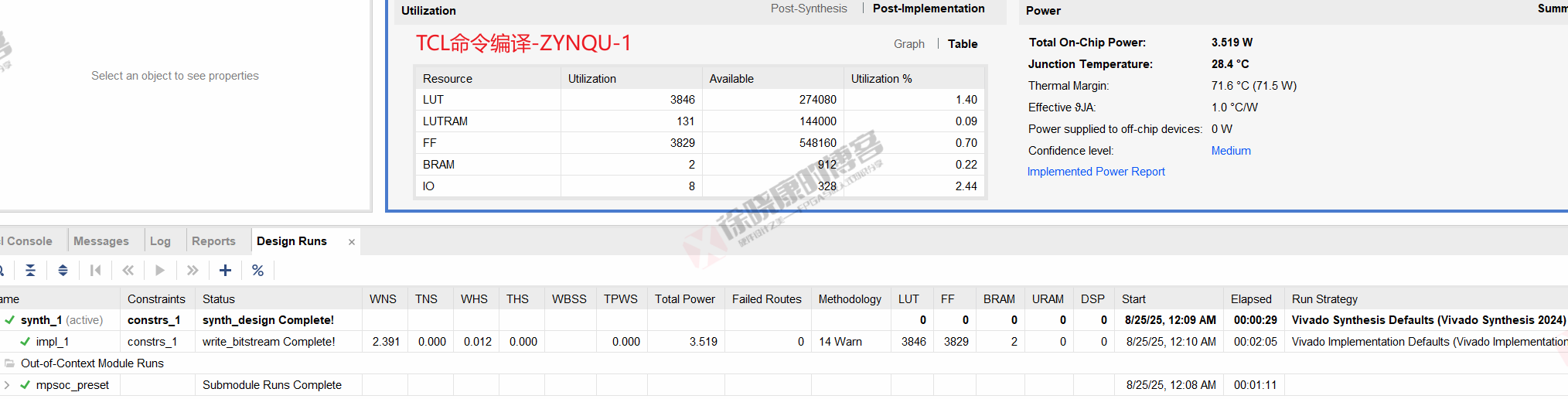
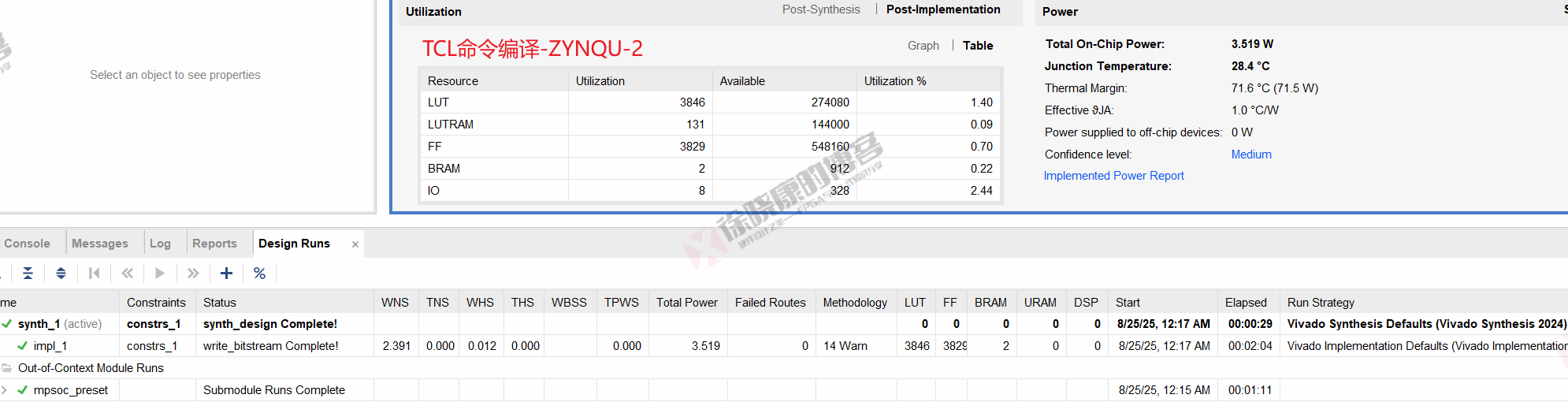
| 实验编号 | OOC | 综合 | 实现 | 合计 |
|---|---|---|---|---|
| Tcl-Project Mode-ZYNQU-1 | 1m11s | 29s | 2m05s | 3m45s |
| Tcl-Project Mode-ZYNQU-2 | 1m11s | 29s | 2m04s | 3m44s |
| Tcl-Project Mode-ZYNQU-平均 | 1m11s | 29s | 2m04.5s | 3m44.5s |
4.3 Tcl-Non-Project Mode
CPU
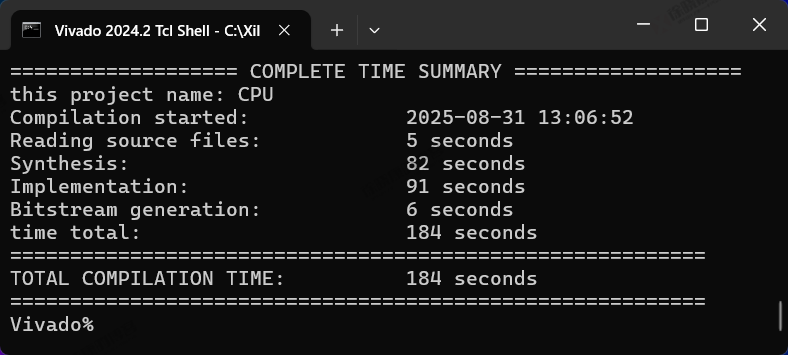
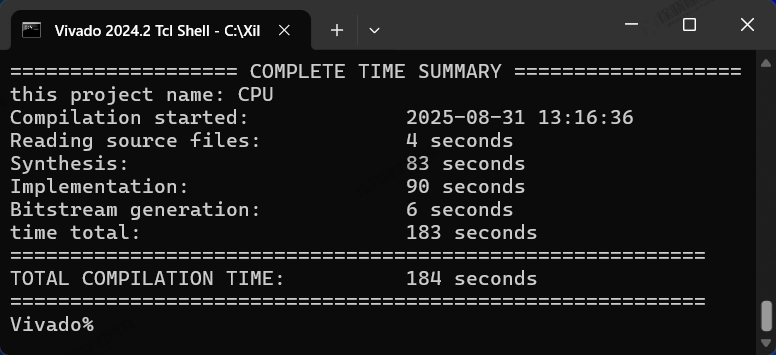
| 实验编号 | OOC | 综合 | 实现 | 合计 |
|---|---|---|---|---|
| Tcl-Non-Project Mode-CPU-1 | 0 | 5+82=87s | 91+6=97s | 184s=3m04s |
| Tcl-Non-Project Mode-CPU-2 | 0 | 4+83=87s | 90+6=96s | 183s=3m03s |
| Tcl-Non-Project Mode-CPU-平均 | 0 | 1m27s | 1m36.5s | 3m03.5s |
MB
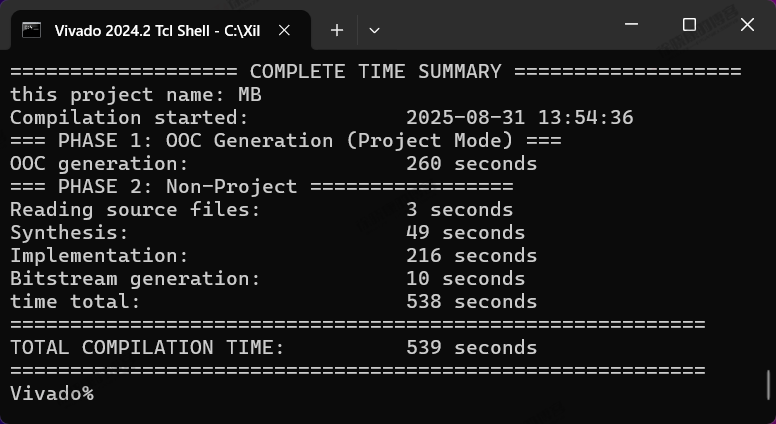
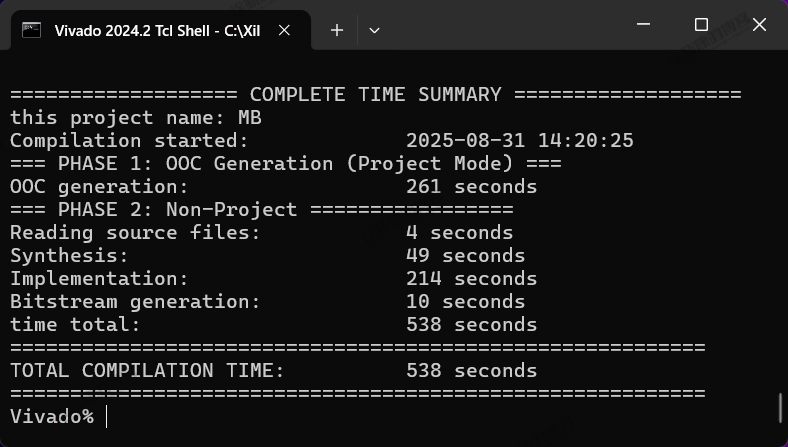
| 实验编号 | OOC | 综合 | 实现 | 合计 |
|---|---|---|---|---|
| Tcl-Non-Project Mode-MB-1 | 260s | 3+49=52s | 216+10=226s | 538s=8m58s |
| Tcl-Non-Project Mode-MB-2 | 261s | 4+49=53s | 214+10=224s | 538s=8m58s |
| Tcl-Non-Project Mode-MB-平均 | 4m20.5s | 52.5s | 3m45s | 8m58s |
ZYNQU
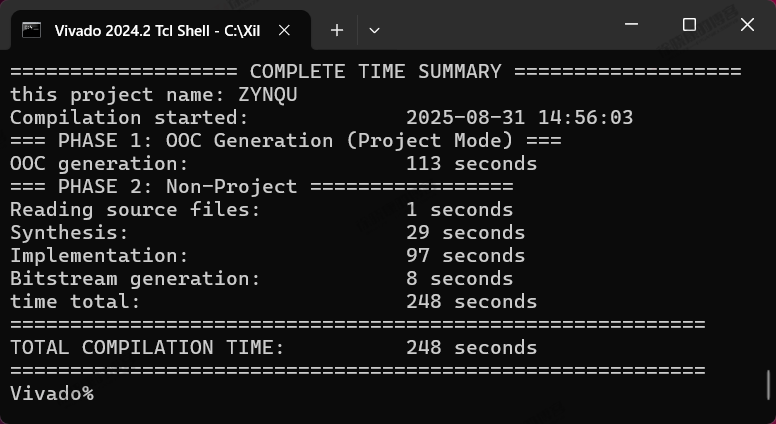
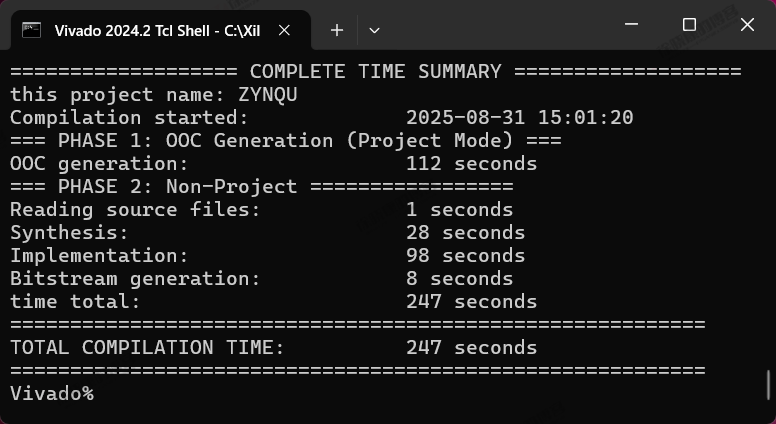
| 实验编号 | OOC | 综合 | 实现 | 合计 |
|---|---|---|---|---|
| Tcl-Non-Project Mode-ZYNQU-1 | 113s | 1+29=30s | 97+8=105s | 248s=4m08s |
| Tcl-Non-Project Mode-ZYNQU-2 | 112s | 1+28=29s | 98+8=105s | 247s=4m07s |
| Tcl-Non-Project Mode-ZYNQU-平均 | 1m52.5s | 29.5s | 1m45s | 4m07.5s |
五、实验结果统计与分析
| 实验条件/平均编译时间/示例工程 | CPU | MB | ZYNQU |
|---|---|---|---|
| 普通GUI模式 | 3m09s | 8m01s | 3m36s |
| Tcl-Project Mode | 3m09s (0.00%) |
8m07s (+1.25%) |
3m44.5s (+3.94%) |
| Tcl-Non-Project Mode | 3m03.5s (-2.91%) |
8m58s (+11.85%) |
4m07.5s (+14.58%) |
由以上实验数据我们可以得出结论:
-
Tcl-Project模式无法提高编译速度,甚至比gui模式更慢 -
Tcl-Non-Project模式同样无法提高编译速度,甚至比gui模式慢很多。
但这里需要说明,文中的Non-Project模式的OOC部分还是采用的Project模式,因为对于含有Block Design的工程,各种依赖关系比较复杂,非工程模式处理起来存在困难。所以,脚本中打开和关闭工程可能会消耗几秒时间。
但是,非工程模式显然慢的比较多,对于MB工程慢57s,对于ZYNQU工程慢31.5s,这种差距只能说明此模式确实要慢一些。而对于网上传的非工程模式更快的说法,有两种可能原因:
-
非工程模式比较灵活,工程模式使用默认综合策略和默认报告策略,非工程模式中则无须按照这些步骤,甚至可以不生成任何报告,做的事情少了,花费时间自然少了,但这并不非工程模式的编译速度上的固有优势,只是因为执行步骤少了而已;
-
以讹传讹,本身就是乱说的。
当然,也可能是我的实验错了,毕竟样本数还是少了点。另外,实验工程都是用的示例工程,相关tcl脚本文末也有分享,想复验实验的同学可自行验证。
结论,Tcl-Project模式和Tcl-Non-Project模式都无法提高编译速度。
六、测试工程与Tcl脚本分享
Tcl工程模式脚本:ProjectMode.tcl
Tcl非工程模式脚本:Non-Project-CPU.tcl;Non-Project-MB.tcl;Non-Project-ZYNQU.tcl
在Gitee和Github开源,两仓库同步。
Gitee: https://gitee.com/xuxiaokang/vivado-tcl
Github: https://github.com/zhengzhideakang/Vivado-Tcl
本系列文章的所有测试工程,如下图所示。
均通过网盘分享。
欢迎大家关注我的微信公众号:徐晓康的博客,回复以下6位数字获取网盘链接。
981520
建议复制过去不会码错字!
如果本文对你有所帮助,欢迎点赞、转发、收藏、评论让更多人看到,赞赏支持就更好了。
如果对文章内容有疑问,请务必清楚描述问题,留言评论或私信告知我,我看到会回复。

徐晓康的博客持续分享高质量硬件、FPGA与嵌入式知识,软件,工具等内容,欢迎大家关注。