

前言
本文为《如何提高Vivado编译速度》系列文章的最终篇。本文将会对本系列之前发布的所有文章进行总结,最终给出提高Vivado编译速度的建议。
仅关注结果的同学其实只看这一篇文章就够了,如果对某个影响因素的结论有疑问,可再去相应的文章详细查看。
本系列所有文章均详细说明了测试用的示例工程,确保各位同学可方便的在自己电脑上复现实验,同时也给出了测试截图,保证数据真实可信。
一、《如何提高Vivado编译速度》系列文章概述
1.1 如何提高vivado编译速度01–编译速度影响因素与对比实验设计
原文地址:如何提高vivado编译速度01–编译速度影响因素与对比实验设计
本文是《如何提高Vivado编译速度》系列的基础介绍文章,文中详细介绍了后续所有测试基于的硬件平台、测试工程以及实验条件。
1)硬件平台:
-
CPU-AMD 9950X,内存-DDR5 6400MHz
-
操作系统-Win11 专业版 24H2
2)测试工程均为Vivado自带示例工程,分别为:
-
CPU–纯Verilog代码工程 -
MB–软核MicroBlaze工程 -
ZYNQU–硬核ZYNQ UltraScale+MPSoC工程
选取它们作为测试工程主要出于以下几点考虑:
-
示例工程,方便其他人复刻实验
-
工程类型不同,更能说明一般情况
-
复杂度中等,便于多次编译
-
通用性强,在各个Vivado版本中都能直接新建
3)实验条件:
-
没有特别说明时,综合和实验策略使用Vivado默认策略 -
编译期间,尽可能关闭所有后台程序,并保证Vivado一直处于前台,不进行其它任何操作 -
单一变量,所有测试均在保证单一变量的情况下进行,除去要研究的影响因素外,每次实验的其它条件保持一致 -
多次实验,同一条件,最少进行两次实验,并确保两次实验的编译时间差值在10s以内,这时才认为实验数据真实可信。在实际操作中,基本每种实验都进行了4~10次
本文是本系列后续文章的基础,后续各个文章均在研究“某单一变量”对Vivado编译速度的影响,而其它条件,如无特别说明,则以本文说明的实验条件为准。
1.2 如何提高Vivado编译速度02–最大线程与使用线程对编译速度的影响
原文地址:如何提高Vivado编译速度02–最大线程与使用线程对编译速度的影响
最大线程可通过下图所示命令进行查看和设置.
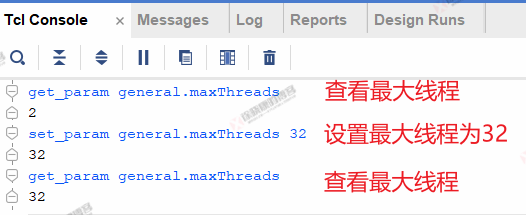
上述命令仅在当前打开的Vivado中生效,关闭Vivado再打开后需要重新设置。
一种永久设置最大线程的办法是在Vivado安装路径的scripts文件夹中新建Vivado_init.Tcl,将set_param general.maxThreads 32命令添加到此Tcl文件中,如下图所示,Vivado启动会自动加载此文件。
使用线程指的是编译时弹出的一个对话框中让我们选择的jobs数,如下图所示。
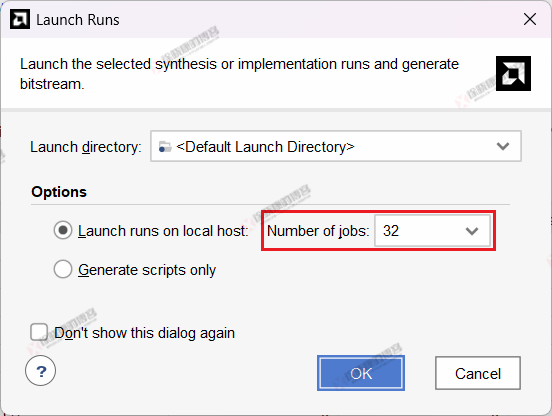
实验结论表明:
-
最大线程影响编译速度,最大线程设置为32时编译速度明显快于最大线程设置为2时
-
使用线程,Vivado最多可利用的线程大概为16,使用线程32与使用线程16时的编译速度几乎一样
小结:必须把最大线程设到最大值32并设置成Vivado启动自动设置。
1.3 如何提高Vivado编译速度03–CPU和内存频率对编译速度的影响
原文地址:如何提高Vivado编译速度03–CPU和内存频率对编译速度的影响
因实验硬件条件有效,本文以CPU是否超频 + 内存是否超频 + 12i7笔记本作为5种测试条件进行实验。结果表明:
-
CPU超频对缩短Vivado编译时间有帮助,约2%,这也跟超频的程度有关,我这个超频策略还是很保守的;
-
内存超频(5600MHz -> 6400MHz)对缩短Vivado编译时间有帮助,约3%,也比较微小;
-
当CPU和内存升级幅度很大时,如CPU从12代i7升级到AMD 9950X,内存从4800MHz升级到6400MHz,编译时间大概缩短到了原来的60%。
小结:CPU和内存的性能提升均能缩短Vivado编译时间,硬件性能的大提升会带来“飞跃般”的变化,且工程越复杂提升越明显。
1.4 如何提高Vivado编译速度04–哪个版本的Vivado编译最快
原文地址:如何提高Vivado编译速度04–哪个版本的Vivado编译最快
本文基于示例工程,测试了各个Vivado版本(包括2018.3, 2019.2, 2020.2,2021.2,2022.2,2023.2,2024.2,2025.1)下的编译速度。

结论:
-
Vivado 2025.1和Vivado 2023.2都不行,与Vivado 2024.2相比均有较大差距,其中2023.2很差
-
Vivado 2022.2、Vivado 2021.2和Vivado 2020.2还行,整体编译速度与Vivado 2024.2相当。但对于纯Verilog工程(CPU),2024.2还是遥遥领先
小结:建议选择Vivado 2024.2作为主力FPGA开发工具
1.5 如何提高Vivado编译速度05–Ubuntu下的Vivado比Win11下的编译更快?
原文地址:如何提高Vivado编译速度05–Ubuntu下的Vivado比Win11下的编译更快?
本文在VMware Workstation Pro 17.6.3中运行Ubuntu 24.04.2 LTS镜像,并在虚拟机设置中将CPU和内存设置为能设置的最大值,以此尽量用虚拟机模拟物理机的性能。

本文除了CPU、MB、ZYNQU三个基础的测试工程外,还新增了更复杂的VCT测试工程。实验结论:
-
当工程比较简单时,Win11和Ubuntu几乎没有区别;
-
当工程较复杂时,Ubuntu下编译更快,大约能缩短22%的编译时间。考虑到本次实验是在虚拟机中运行的Ubuntu,而非实际操作系统,通常来说,实际操作系统性能会更好,所以,实际操作系统的Ubuntu下,Vivado编译时间可能能缩短25%甚至更多。
小结:如果编译复杂工程,可选择Ubuntu提高编译速度。
1.6 如何提高Vivado编译速度06–禁用报告和抑制信息能否加快编译速度?
原文地址:如何提高Vivado编译速度06–禁用报告和抑制信息能否加快编译速度?
本文通过使用No Reports的报告策略来禁用报告以及相关Tcl命令来抑制所有信息输出,测试这两个因素是否影响编译速度。
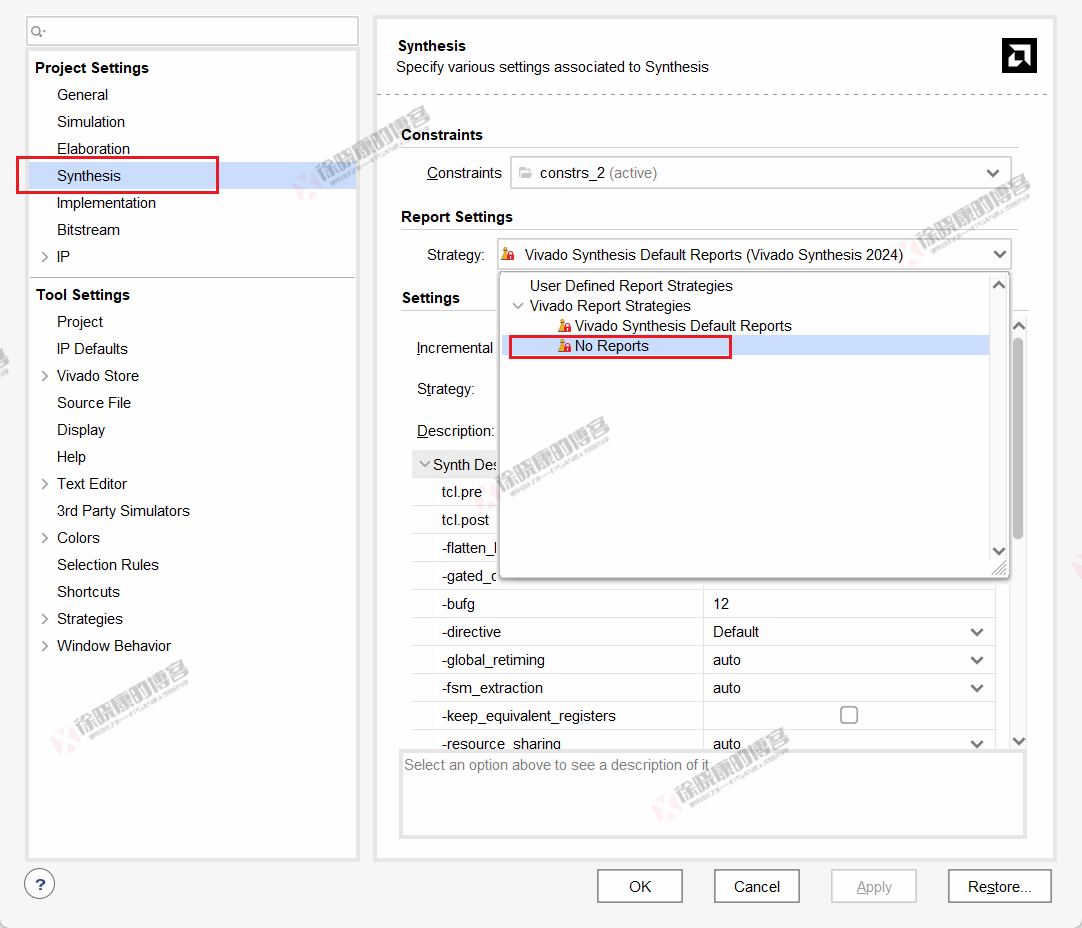
实验结论:
-
No Reports模式对编译速度提升影响微弱,但有较大副作用,看不到资源消耗、功耗和时序信息了;
-
抑制信息对编译速度无影响。
小结:No Reports与抑制信息均属于“邪修”手段,对编译速度影响微弱,不应该使用。
1.7 如何提高Vivado编译速度07–不同的综合和实现策略是否影响编译速度?影响多大?
原文地址:如何提高Vivado编译速度07–不同的综合和实现策略是否影响编译速度?影响多大?
本文测试了编译时间优化策略相比于默认策略是否能显著提升编译速度,
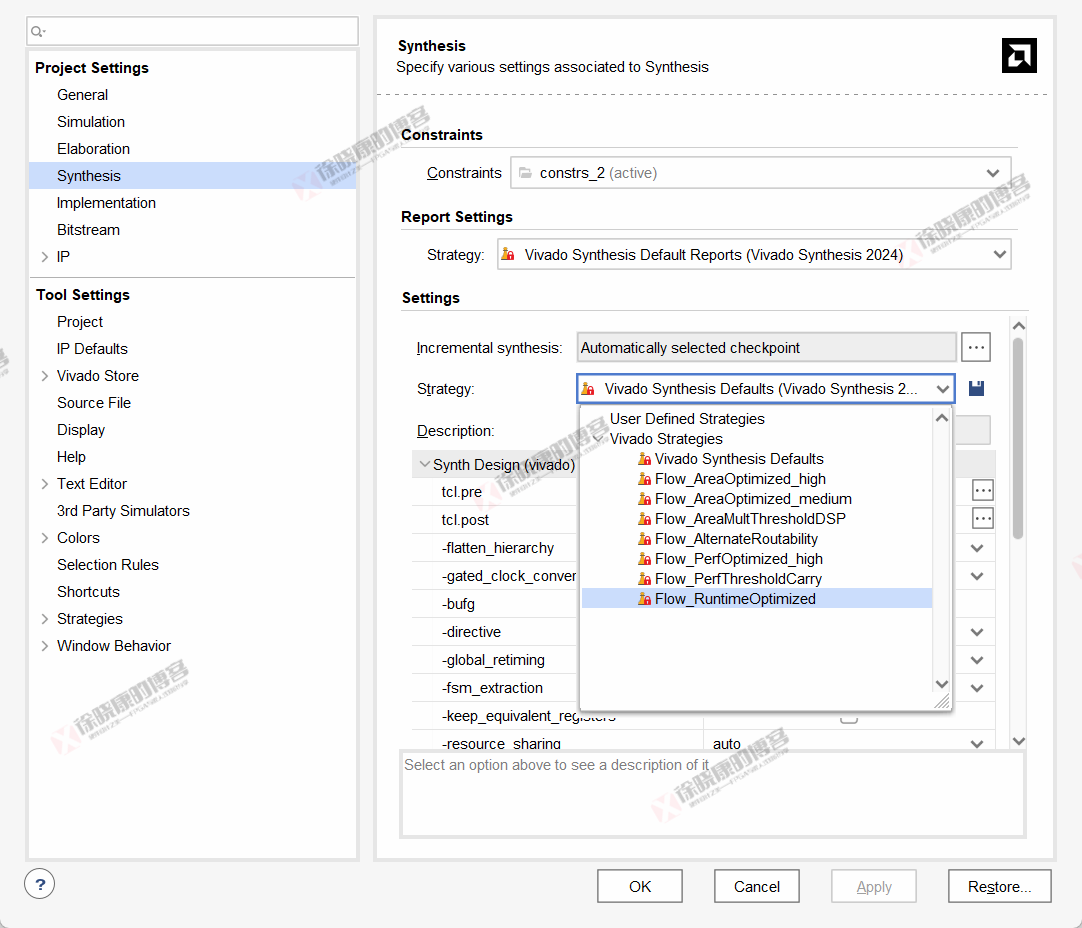
实验结论:
-
编译时间优化策略有时能提高一些编译速度,但效果并不明显,进一步对比会发现,时间主要缩短在实现阶段;
-
编译时间优化策略并不总是起作用,在ZYNQU工程中它就没有作用;
-
编译时间优化策略可能导致实现失败(如在VCT工程中),一个可能的原因是编译时间优化策略的时序优化能力较差,使得复杂工程中时序难以满足要求,进而导致Vivado反复尝试去满足时序要求,最终导致实现失败。
小结:如果电脑确实跑得比较慢,本着能节约点时间也好的想法,可以在开发前期尝试下编译时间优化策略,对比下与默认策略相比编译时间能缩短多少,开发后期再换回默认策略或其他优化面积/速度的策略,这样能加快些开发进度。如果发现编译出错,及时换回默认策略。
1.8 如何提高Vivado编译速度08–不使用GUI以及Non-Project Mode能提升编译速度吗?
原文地址:如何提高Vivado编译速度08–不使用GUI以及Non-Project Mode能提升编译速度吗?
本文测试了Vivado的两种非GUI模式即Tcl-Project Mode和Tcl-Non-Project Mode能否提高编译速度。
实验结论:
-
Tcl-Project模式无法提高编译速度,甚至比gui模式更慢
-
Tcl-Non-Project模式同样无法提高编译速度,甚至比gui模式慢很多。
小结:使用非GUI模式无法提升编译速度。
1.9 如何提高Vivado编译速度09–使用模块化综合(OOC)能提升编译速度吗?
原文地址:如何提高Vivado编译速度09–使用模块化综合(OOC)能提升编译速度吗?
本文对比了OOC per IP 与 Global 两种模式在工程第一次编译情况下的耗时。
实验结论:
-
OOC和Global并没有出现哪种模式一直领先的情况; -
基于MB的数据,OOC大幅领先,可能对于软核工程,OOC会更好; -
对于硬核工程(ZYNQU和VCT),OOC和Global差距微小。
小结:OOC和Global在第一次编译时差距不大,但在后续编译中,OOC因为其工作原理,未改动的IP无需重新编译,最极限情况是所有IP未更改,此时OOC模式将节约整个OOC阶段的时间。所以,从提升编译速度的方面考虑,建议总是使用OOC模式。
二、《如何提高Vivado编译速度》系列文章的总结与建议
2.1 建议使用的手段
根据上述文章实验验证的可提升Vivado编译速度的因素,建议各位同学通过以下手段提升编译速度:
-
升级电脑,这个绝对是提升最大的,参考12代i7 -> 9950X,内存4800MHz -> 6400MHz,编译时间缩到到了原来的60%;
-
解锁Vivado最大线程限制(默认为2),把最大线程设到最大值32并设置成Vivado启动自动设置;
-
选择Vivado 2024.2作为主力FPGA开发工具,此版本编译速度最快,特别是相对2023.2和2025.1快很多;
-
使用Ubuntu编译复杂工程,相对于Win11,Ubuntu下编译更快,对于复杂工程大约能缩短22%的编译时间;
-
使用模块化综合(OOC),这是默认设置,在第一次编译工程时Global和OOC差距很小,但后续OOC会明显快于Global;
-
使用增量编译,包括增量综合和增量实现,这也是默认设置,本系列文章未实测增量编译的效果,因为它的效果显然跟工程的改动量相关,无法量化,但增量编译是Vivado软件的亮点之一,实际使用中确认可以显著缩短编译时间。
2.2 仅建议尝试的手段
仅建议尝试评估后使用,而不建议常态化使用的手段:
-
使用编译时间优化策略,此策略可用于前期快速功能开发,中后期需切换为默认策略或其它性能优化策略。但如果你担心此策略有其它可能的副作用,那就不用。
2.3 不建议使用的手段
根据上述文章实验验证的无法提升Vivado编译速度的因素,建议各位同学不要使用以下手段:
-
禁用报告和抑制信息,影响微弱,副作用极大,建议不用; -
非GUI模式,即使用Tcl-Project模式或Tcl-NonProject模式,无法提升编译速度,从提升速度角度考虑,不要使用。当然你可以用Tcl脚本管理工程。
三、回答一些粉丝的疑问
3.1 工程太小,没有说服力?
实验电脑配置很高,在此配置下VCT工程需要16m以上,MB工程需要8m以上,并不算小工程。
我当然可以选择更复杂的工程,但那样将花费太多时间来进行各种实验。
另外出于方便各位同学重复实验的角度考虑,这些工程的复杂度是合适的。
3.2 物理机下运行Ubuntu会不会Vivado编译更快?
合理分析:会。
虚拟机性能必然弱于物理机,但大部分人可能没有物理机运行Ubuntu的条件。
不建议给电脑装双系统,过程繁琐易出错,切换使用也不甚方便。
后续有时间会研究,如何在虚拟机Ubuntu中编译,再快速切换到Windows中进行下载调试,这样即可利用Ubuntu的速度,也可利用Windows的便捷,两全其美。感兴趣的同学请保持关注。
3.3 9950X3D下Vivado比9950X编译更快?
合理分析:不会。
3D V-Cache(三维堆叠缓存)对游戏性能提升显著,主要是因为游戏存在大量随机数据访问,大缓存能有效降低延迟。然而,Vivado编译流程涉及的大量数据处理通常顺序访问居多,并且数据集远大于L3缓存,因此大容量缓存带来的收益可能非常有限。编译速度的瓶颈更多在于CPU核心数、频率以及内存带宽。
9950X在运行Vivado编译时,其速度很可能会比9950X3D略有优势,或者两者差异极小。
3.4 Tcl模式不能提升编译速度吗?为什么我用Tcl比gui模式快?
在上述文章中用两种Tcl模式测试了CPU、MB和ZYNQU三个工程,得出了结论,相比较正常GUI工程模式,Tcl模式无法提升编译速度。
有粉丝质疑工程太小了,结论不对,为什么我用tcl模式编译会更快?
文章中未将 VCT 工程纳入 Tcl-Non-Project 模式的测试,主要因为 VCT 工程的 IP 依赖关系复杂,难以用该模式快速搭建编译流。但我用Tcl-Project模式是跑过VCT的,确认了没有提升,才下的结论。后续我又跑了几遍,给出Tcl-Project-VCT编译时间截图如下。


| 实验编号 | OOC | 综合 | 实现 | 合计 |
|---|---|---|---|---|
| Tcl-Project-VCT-1 | 3m11s | 3m40s | 9m23s | 16m14s |
| Tcl-Project-VCT-2 | 3m12s | 3m39s | 9m24s | 16m15s |
| Tcl-Project-VCT-平均 | 3m11.5s | 3m39.5s | 9m23.5s | 16m14.5s |
数据对比:
| 实验条件/平均编译时间/示例工程 | CPU | MB | ZYNQU | VCT |
|---|---|---|---|---|
| 普通GUI模式 | 3m09s | 8m01s | 3m36s | 16m01s |
| Tcl-Project Mode | 3m09s (0.00%) |
8m07s (+1.25%) |
3m44.5s (+3.94%) |
16m14.5s (+1.40%) |
| Tcl-Non-Project Mode | 3m03.5s (-2.91%) |
8m58s (+11.85%) |
4m07.5s (+14.58%) |
— |
可见Tcl的两种模式相对GUI模式均没有提升编译速度。
四、最后
如果仍有同学对测试结论有质疑,我希望你能拿出测试数据,我欢迎一切基于数据的讨论。
科学实验具有可重复性,本系列文章已经分享了所有测试工程和相关脚本,说明了测试条件,每个人都可以重复我的测试。当然,硬件平台会有不同,但这只会影响编译的绝对时间,各个条件下编译速度的相对关系不会改变,不影响最终结论。
关于如何提升Vivado编译速度,网上众说纷纭,一些结论和我的相反,相信谁?谁才是对的?实践是检验真理的唯一标准,各位同学不妨自己试一试。如果结论确和我的不一样,请务必告知我,我们共同进步。
“天下FPGA开发者苦Vivado编译慢久矣”,每个Vivado使用者都希望能尽可能提升编译速度,那究竟有哪些办法呢?这些办法真的有效果吗?解决这些问题是本系列文章的写作初衷。希望本系列文章能帮助各位同学扫除疑惑,在一种“这已经是此硬件条件下的最优解”的心态中进行开发学习,这种感觉真的很棒。
如果本文对你有所帮助,欢迎点赞、转发、收藏、评论让更多人看到,赞赏支持就更好了。
如果对文章内容有疑问,请务必清楚描述问题,留言评论或私信告知我,我看到会回复。

徐晓康的博客持续分享高质量硬件、FPGA与嵌入式知识,软件,工具等内容,欢迎大家关注。